大型互联网系统里数据库切换那事儿,怎么搞才稳妥又不出大问题

主要参考了58同城沈剑团队的实际经验、阿里巴巴的标准化流程以及一些技术社区如CSDN上关于灰度发布的讨论)
大型互联网系统的数据库切换,绝对不是找个夜深人静的时候,发个公告停服几小时,然后像给汽车换轮胎一样把数据库一换了之,那样做,轻则服务长时间不可用,用户体验暴跌,重则数据错乱,甚至无法回退,造成严重的生产事故,稳妥的做法,核心思想就八个字:平滑过渡,可进可退,整个过程更像是一次小心翼翼的“器官移植”,要让新老系统并行工作一段时间,确保新器官完全正常后,再逐步停掉老的。
具体怎么搞,可以分为几个关键阶段:
第一阶段:战前准备,磨刀不误砍柴工
这个阶段是所有后续操作的基础,准备不充分,后面全是坑。
- 数据同步是头等大事:你不能等到切换那一刻才把数据倒过去,必须提前让新老数据库“数据同步”,通常的做法是,在业务低峰期,比如凌晨,先做一次全量数据拷贝,把老数据库的数据完整地复制到新数据库,从这一刻开始,启用一种叫“实时同步”的工具(比如阿里巴巴开源的Canal,或者一些商业软件),把老数据库上后续产生的所有数据变更(增、删、改),像录影一样实时地同步到新数据库,这样,新数据库的数据就在不断追平老数据库,为切换做准备,这个过程可能要持续好几天甚至更久,以确保同步稳定无误。
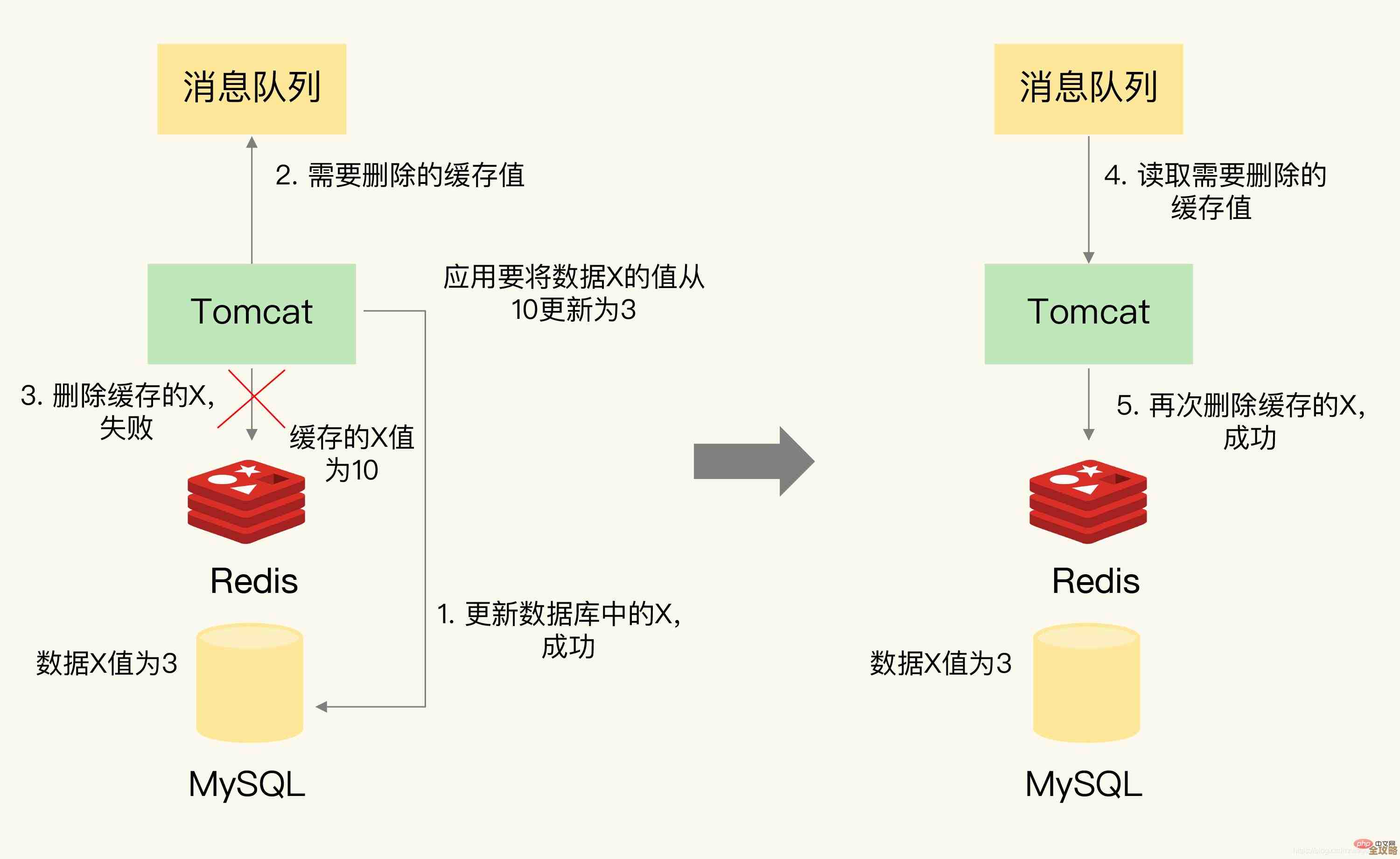
- 代码要具备“双写”能力:这是实现平滑切换的关键,你需要提前改造应用程序的代码,让它在一段时间内,每次处理写请求(比如用户发布内容、修改信息)时,同时往老数据库和新数据库都写一份,这样,无论最后用哪个库,数据都是一致的,读请求仍然只走老数据库,因为新库可能还在追数据,性能或不稳定,这个双写功能需要一个开关来控制,比如在系统的配置中心里设置一个开关,能一键开启或关闭双写。
- 充分测试,不留死角:新数据库的性能如何?能不能扛得住真实的流量?双写逻辑有没有bug?同步工具会不会丢数据?这些都需要在模拟真实环境的测试库里反复验证,要进行压力测试、异常测试(比如模拟同步中断怎么办)、数据一致性核对等,特别是数据一致性,要开发核对脚本,定期比对两个库的数据差异,确保同步是精准的。
第二阶段:逐步切换,小步快跑看效果
准备工作万无一失后,就进入最核心的切换阶段,这个过程一定是逐步的,而不是一刀切。
- 开启双写,但以老库为准:在业务低峰期,通过配置开关打开双写功能,所有写操作同时落入两个库,但业务逻辑仍然以老库的写入结果为准(比如返回成功与否看老库),这样做是为了让新库在真实流量下“热身”,同时继续通过同步工具保证万一新库写失败,还有老库的数据同步过来兜底。
- 灰度读切换,从非核心业务开始:这是“可进可退”思想的典型体现,你不能把所有用户的查询请求一下子都切到新库,应该先选择一小部分用户(比如内部员工),或者一些不重要的、只读的非核心业务功能,将它们的读请求引导到新数据库上,观察一段时间(比如几小时或一天),看新库的响应速度是否正常,监控系统有没有报错,业务逻辑是否正确。
- 逐步扩大读流量:如果灰度读一切正常,就可以像拧水龙头一样,逐步加大导到新库的读流量比例,比如从5%的用户,扩大到20%,再到50%,最后到100%,每扩大一步,都要停下来观察,确认没问题再进行下一步,这个过程可能持续一天或更久。
- 关键时刻:停同步,切写入:当100%的读流量都在新库上稳定运行一段时间后,最惊险的一步来了,要停掉老库到新库的实时同步工具,防止后续操作产生数据混乱,将业务的“写主体”正式切换到新库,也就是说,之后所有的写操作,以新库的写入结果为准,因为之前一直开着双写,所以这个切换会非常快,几乎对用户无感。
- 老库降级为备胎:切换完成后,老库还不能立刻删除,它需要作为“备胎”保留一段时间(比如一周或一个月),在此期间,可以关闭双写功能,只让新库提供服务,可以反向开启一个新库到老库的同步,让老库保持数据更新,这样万一新库出现预想不到的严重问题,我们可以快速切回老库,保证业务不中断,这才是真正的“可退”。
第三阶段:打扫战场,清理旧代码
当新数据库稳定运行了足够长的时间,大家都有信心之后,就可以进行收尾工作:下线老数据库,移除应用程序中为双写和切换所写的临时代码和开关,至此,一次稳妥的数据库切换才算圆满结束。
大型系统的数据库切换,不是一个技术点的强攻,而是一个涉及技术、流程、协作的系统工程,它的精髓在于通过一系列缜密的步骤,将一个大风险拆解成无数个小风险点,并在每个环节都设计好回退方案,从而确保整个过程的平稳可控。

本文由芮以莲于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75461.html