Redis面试那些事儿,帮你轻松搞定梦寐以求的工作机会

(引用来源:掘金社区、CSDN博客、GitHub上面经分享、个人面试经验)
说到找工作,尤其是技术岗,Redis现在几乎是面试官必问的技能点,不管你是初级还是高级开发,都绕不开它,你别看它只是个缓存,里面的门道可多了,问得深了浅了都能看出你的水平,今天咱们就聊聊Redis面试里那些高频出现的事儿,帮你心里有个底。
开场白:别小看“什么是Redis”这个问题
很多面试喜欢从这里开始,你可千万别只说“Redis是个缓存数据库”,这太单薄了,你得准备个丰满点的答案。
(引用来源:多数面试官的开场习惯) 你可以这么说:Redis全称是Remote Dictionary Server,远程字典服务,它首先是一个基于内存的Key-Value存储系统,所以速度非常快,常被用作缓存,来解决传统数据库(像MySQL)读写慢、扛不住高并发的问题,但它的本事不止于此,它还提供了丰富的数据结构,比如字符串、列表、哈希、集合等等,这让它能搞定很多复杂的业务场景,比如排行榜、好友关注、秒杀库存扣减等,它支持数据持久化,可以把内存数据存到硬盘上,防止重启后数据丢失,它更像是一个高性能的、多功能的NoSQL数据库。
你看,这样回答,既说出了核心(内存KV缓存),又展示了它的广度和特点(数据结构丰富、持久化),一下子就把格局打开了。
持久化:RDB和AOF是必考点,得掰扯清楚
这是Redis面试的重中之重,几乎必问,你光记住名字不行,得理解它们是怎么工作的,以及各自的优缺点。

(引用来源:几乎所有Redis面试题集) RDB(快照):就像是给数据库拍一张全景照片,在特定时间点,把内存里所有的数据完整地保存到一个叫dump.rdb的文件里,优点是文件紧凑,恢复大数据集时速度很快,缺点是因为是定时拍快照,如果两次快照之间服务器宕机,这期间的数据就丢了。
AOF(追加日志):它不拍照片,而是像个记账先生,把每一个写操作命令都记录在一个日志文件里,当Redis重启时,就把这个日志里的命令重新执行一遍,来恢复数据,优点是数据安全性高,最多损失一秒的数据(如果你配置成每秒同步一次),缺点是日志文件通常会比RDB文件大,而且恢复速度慢。
面试官很可能会追问:“那生产环境该怎么选?” 这时候你就可以说,通常两者结合使用,用AOF来保证数据不丢失,作为数据恢复的第一选择;同时定期用RDB做一个冷备,因为RDB恢复快,而且便于做历史归档或灾难恢复。
缓存问题:穿透、击穿、雪崩,一个都不能少
只要你说了Redis用作缓存,面试官九成会问这“三兄弟”,你得能清晰地解释它们分别是什么,以及怎么解决。
(引用来源:高并发系统设计经典问题)
缓存穿透:指的是查询一个根本不存在的数据,这个数据在缓存和数据库中都没有,所以每次请求都会直接打到数据库上,就像缓存不存在一样,解决办法很简单,一种是把这种不存在的数据也缓存在Redis里,设置个短的过期时间,比如key: null,这样下次再来问就直接返回null了,另一种是用布隆过滤器(Bloom Filter)在查询缓存前先拦一道,如果布隆过滤器说没有,那肯定没有,直接返回。

缓存击穿:指的是一个非常热点的key,在它过期的瞬间,有大量并发请求过来,这些请求发现缓存没了,就全都冲到数据库去查,把数据库压垮,解决办法是让热点key永不过期,或者使用互斥锁(分布式锁),只让一个请求去数据库查,其他请求等着,查完回填缓存后,大家再从缓存里读。
缓存雪崩:指的是缓存中大量的key在同一时间过期,或者Redis服务器直接宕机了,导致所有请求都涌向数据库,造成数据库压力巨大甚至崩溃,解决办法是给不同的key设置随机的过期时间,避免同时失效,如果是Redis宕机,那就需要用到Redis的高可用方案,比如主从复制、哨兵模式或者集群模式,保证服务不中断。
数据结构:别只知道String,说说其他的应用场景
Redis可不是简单的键值对,它的价值在于那些灵活的数据结构。
(引用来源:Redis官方文档及实战案例)
比如面试官可能会问:“用Redis怎么实现一个排行榜?” 这时候你就要想到有序集合(Sorted Set),它可以根据一个分数(score)来排序,非常适合做排行榜,再比如,“怎么实现一个抽奖系统,保证一个人不会重复中奖?” 你就可以说用集合(Set),因为它里面的元素是不重复的,把参与过抽奖的用户ID放进去,用sismember命令一查就知道有没有重复。
还有列表(List) 可以做简单的消息队列,哈希(Hash) 非常适合存储对象信息,比如用户信息,一次就能存取一个对象的多个字段,比用多个String键要高效,能结合具体业务场景说出数据结构的应用,会让面试官觉得你不是死记硬背,而是真正会用。

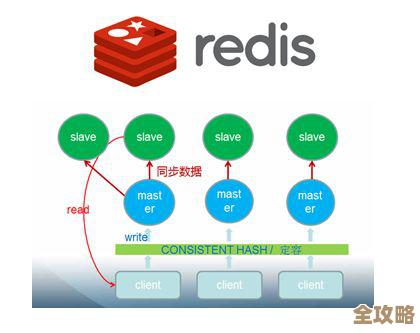
高可用和集群:迈向高级开发的台阶
如果你面试的是中高级岗位,这方面的问题就跑不掉了。
(引用来源:大型互联网公司技术面试深度考察点) 主从复制:这是基础,一个主节点(Master)负责写,多个从节点(Slave)负责读,主节点把数据同步给从节点,这样实现了读写分离和数据的备份。
哨兵(Sentinel):它是主从模式的“守护者”,哨兵集群会监控主节点和从节点是否活着,如果主节点挂了,哨兵会自动从从节点中选举出一个新的主节点,让系统继续提供服务,实现了高可用。
集群(Cluster):当数据量非常大,一台机器存不下的时候,就需要用集群,它把数据分片(分片)存储在多个节点上,每个节点存一部分数据,这样就实现了海量数据的存储和水平扩展。
你不需要把每个细节都背得滚瓜烂熟,但至少要明白它们各自解决了什么问题(是高可用还是大数据量),以及大致的原理。
面试前最好能准备一两个你用Redis解决实际问题的例子,讲清楚当时遇到了什么挑战,为什么选择Redis,用了它的什么特性,最后效果怎么样,这样的实战故事,比单纯背八股文要加分得多,希望这些“事儿”能帮你在下一次面试中更加从容自信,搞定那个梦寐以求的工作机会!
本文由钊智敏于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75424.html