Kafka分区和组消费到底咋回事?三张图帮你理清楚,别再糊涂了

(根据微信公众号“石杉的架构笔记”的文章内容整理)
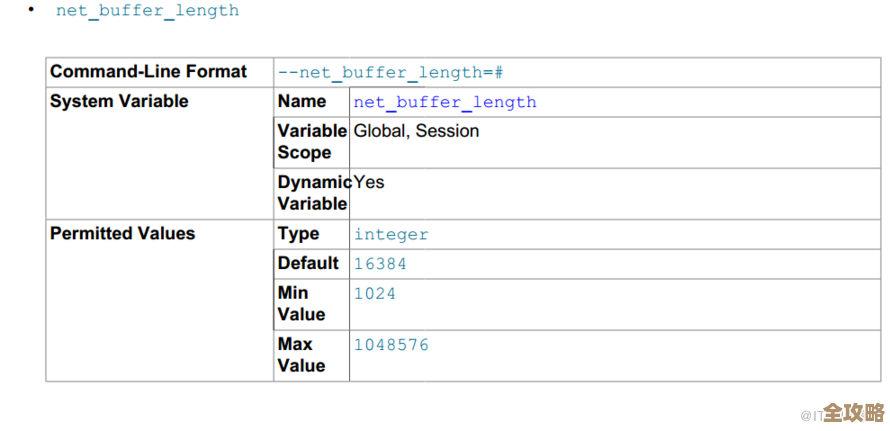
第一张图:一个主题,一个分区,一个消费者
想象一下,Kafka中的一个“主题”就像是一个快递存放点,菜鸟驿站”,这个主题里的消息就是一个个待取的快递。
最开始,最简单的情况是:这个驿站里只有一个货架(这就是一个分区),只有一个快递员(这就是一个消费者)负责从这个唯一的货架上取走快递,然后派送给收件人。
这种情况非常容易理解:
- 货架(分区):只有一个,所有快递(消息)都按顺序摆放在这个货架上。
- 快递员(消费者):只有一个,他按照快递放上货架的先后顺序,一个一个地取走。
这样一来,消息的处理顺序是严格有序的,先放上去的快递先被取走,它的吞吐量很低,因为只有一个快递员在干活,如果快递非常多,这个快递员肯定会忙不过来,造成积压。
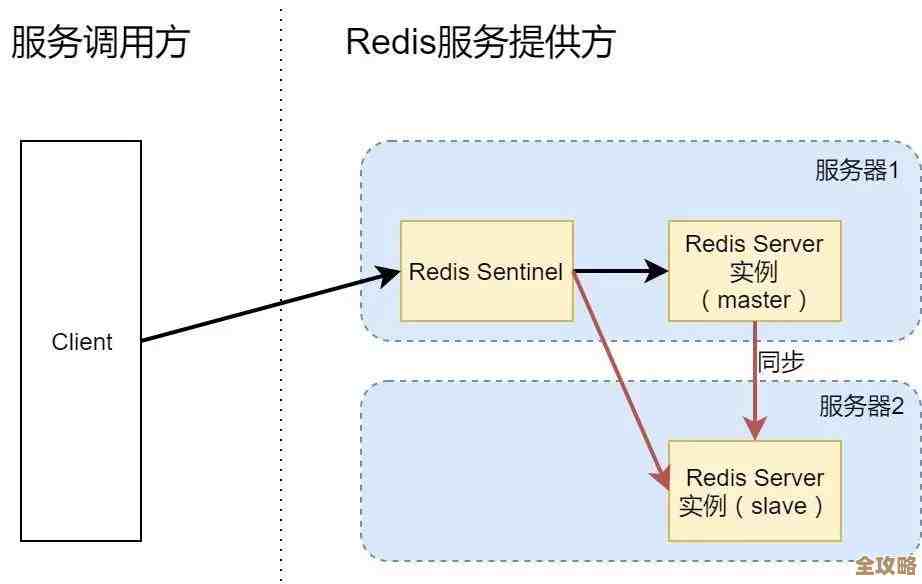
第二张图:一个主题,多个分区,一个消费者组(消费者数=分区数)

快递太多了,一个货架和一个快递员根本处理不过来,怎么办呢?
驿站老板决定进行扩容:他设立了多个一模一样的货架,比如三个(这就是为主题创建了三个分区),他聘请了三个快递员,组成一个“快递小组”(这就是一个消费者组),老板规定:每个快递员固定负责一个货架,货架1的快递只能由快递员A取,货架2的由快递员B取,货架3的由C取。
这就是Kafka实现高吞吐量和并发消费的核心模型:
- 多个货架(多分区):把大量的快递分散到不同的货架上,实现了存储的负载均衡。
- 快递小组(消费者组):小组里的每个成员独立工作,互不干扰。
- 一对一负责制:在一个消费者组内,一个分区在同一时间只能被组内的一个消费者消费,反过来,一个消费者可以负责多个分区,但在本例最理想的情况下,消费者数量和分区数量相等,每人负责一个。
这样一来,三个快递员可以同时干活,取快递的效率变成了原来的三倍,这就是水平扩展的能力,需要注意的是,消息的顺序性保证只在每个分区内部,货架1上的快递顺序依然是固定的,由快递员A按顺序取走,货架1上的第5个快递和货架2上的第5个快递,谁先被取走就不确定了,如果你需要全局严格有序,那就只能回到第一种模型(但会牺牲性能);通常我们通过设计消息键,将需要顺序处理的消息发送到同一个分区,来保证关键消息的顺序性。

第三张图:一个主题,多个分区,一个消费者组(消费者数<分区数)
生意有好有坏,突然有一天,快递量没那么大了,三个快递员有点闲置,驿站老板为了节省成本,让其中一个快递员(比如C)去干别的事了,只剩下快递员A和B。
但是货架还是三个呀,怎么办呢?老板重新分配了任务:手脚麻利的快递员A除了负责原来的货架1,再把空闲出来的货架3也管了,快递员B则继续负责货架2。
这个场景展示了Kafka消费者组的弹性和故障容错能力:
- 动态调整:消费者组里的消费者数量可以增减,Kafka有一个叫“重平衡”的机制,一旦发现有消费者加入或离开,它会自动重新分配分区和消费者的对应关系,确保所有分区都有人消费,不会出现“孤儿货架”。
- 负载不均:快递员A需要干差不多双倍的活,而B则相对轻松,在Kafka中,这可能导致负载不均衡,所以通常我们尽量让消费者数量与分区数量成整数倍关系,以达到均匀分配。
- 故障处理:如果快递员B突然生病了(消费者实例宕机),重平衡机制会立刻触发,原来由B负责的货架2会被重新分配给A,这样,虽然整体速度变慢了,但确保所有快递都不会没人管,服务不会中断。
总结一下核心要点:
- 分区是并行度的单位:想要消费得快,就增加分区,从而允许更多的消费者同时干活。
- 消费者组是逻辑上的消费者单位:组内的消费者共同协作来消费一个主题。
- 组内分区分配原则:一个分区只能被组内的一个消费者消费(点对点模式),但一个消费者可以消费多个分区,这个规则保证了同一条消息不会被组内重复消费。
- 重平衡是保障:它像是一个智能的调度员,在消费者上下线时自动调整任务分配,保证系统的弹性和高可用性。
分区解决了“怎么存能更快”的问题,消费者组解决了“怎么取能更快”以及“如何不掉线”的问题。 把这两者结合起来,就构成了Kafka高吞吐、可伸缩、高可用的消费能力,希望这三张图能让你彻底理清楚它们之间的关系。
本文由歧云亭于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75404.html