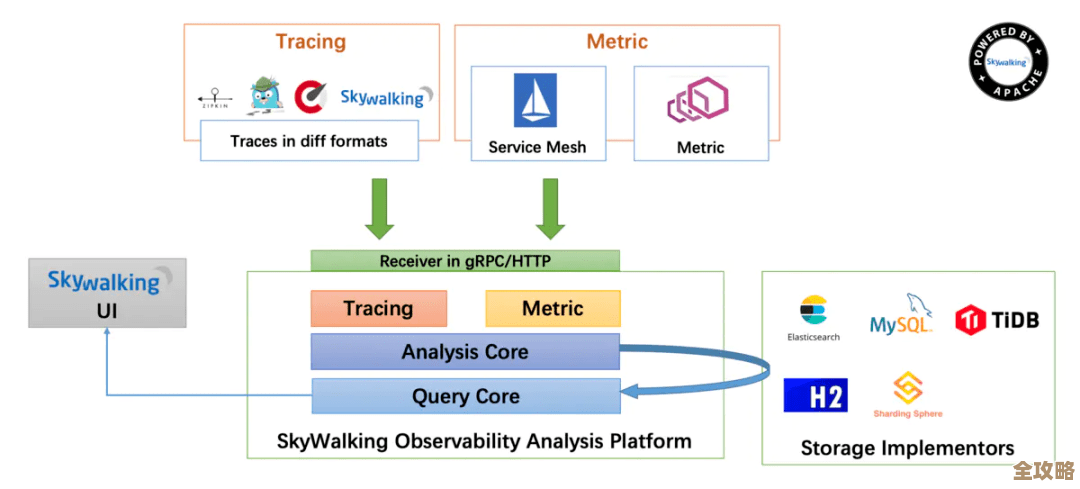
Redis缓存分页那点事儿,聊聊怎么让数据查询快起来

开始)
今天咱们来聊一个实际开发中经常碰到的问题:用Redis做缓存,怎么搞定分页查询,让数据查得快快的,我们都知道,数据库,特别是关系型数据库像MySQL,在数据量大了以后,分页查询(就是咱们常说的“第几页,每页多少条”)会变得越来越慢,尤其是翻到很靠后的页面时,那个LIMIT offset, size语句会让数据库引擎扫描并丢弃大量数据,效率很低,这时候,大家自然会想到用Redis这个内存数据库来当缓存,减轻数据库的压力,但分页这个东西,在Redis里怎么存、怎么取,还真有点讲究,不是简单把数据扔进去就完事了。
最常见的误区:直接缓存分页结果
很多人第一个想到的办法最简单:你不是要查“商品列表第2页,每页10条”吗?那我就在Redis里弄一个键,比如goods:list:page:2:size:10,直接把这一页的10条数据序列化后存进去,下次再有人查这一页,直接从Redis里拿,快得很!

这个方法听起来很美,但问题很大,最大的问题是数据一致性,想象一下,如果后台管理员修改了其中某个商品的信息,或者上架了一个新商品,那么哪些分页会受影响?第一页肯定变了,第二页可能也会变,你得去把所有可能受影响的分页缓存,比如goods:list:page:1:size:10,goods:list:page:2:size:10……全都找出来删掉,这个“找出所有受影响缓存”的操作非常麻烦,甚至可能根本没法精确做到,结果就是,用户看到的是旧的、过期的数据,这种缓存策略的维护成本太高,很容易导致脏数据,所以一般不太推荐用。
更优的方案:缓存整个数据集,在Redis中分页
一个更好的思路是:我们不缓存最终的分页结果,而是把查询条件对应的全部数据ID(或核心字段) 缓存起来,分页的操作,放在Redis里完成。

具体怎么做呢?
- 缓存ID列表:当第一次查询某个条件下的数据时(所有上架中的电子产品”),我们还是得去数据库查,但查回来之后,我们不缓存整个对象列表,而是只把这批数据的主键ID列表,按顺序存到Redis的一个
List或Sorted Set数据结构里,这个键可以叫goods:ids:category:electronics:status:1。 - 在Redis中实现分页:当需要分页时,比如要第2页(page=2, size=10),我们就用Redis的命令来操作,如果用的是
List,就可以使用LRANGE命令:LRANGE key 10 19,这个命令的意思是,从列表中取出索引从10到19的元素(也就是第11到第20个元素,通常我们计算分页起始索引是(page-1)*size),这一步非常快,因为Redis是基于内存的,列表的随机访问效率很高,完全避免了数据库OFFSET带来的性能问题。 - 缓存具体数据:上一步我们只拿到了10个ID,我们需要用这10个ID去获取每个ID对应的完整商品信息,这里又有一个小技巧,我们通常会提前把每个商品对象都以键值对的形式缓存在Redis里,键名比如是
goods:detail:{id},然后使用MGET命令,一次性把这10个ID对应的商品数据全部取出来,如果发现有某个ID在缓存中不存在(可能过期了),我们再单独去数据库查,并回填到缓存。 - 为什么用Sorted Set? 有时候我们的分页不是简单的按时间倒序,而是有复杂的排序,比如按价格、按销量,这时候
List就不好使了,因为它是有序的,而Sorted Set(有序集合)可以给每个成员(比如商品ID)设置一个分数(score),这个分数可以是价格、销量、综合评分等,查询时,可以用ZRANGEBYSCORE等命令实现按分数范围排序和分页,非常灵活。
这个方案的好处是:
- 维护简单:当某个商品信息更新时,我只需要清除或更新那个具体的商品缓存
goods:detail:123就行了,而顶层的ID列表goods:ids:...可以设置一个合理的过期时间(比如5分钟),即使不主动清除,短时间的脏读也是可以接受的,因为核心数据(商品详情)是新的,如果是对排序有影响的字段更新(比如价格),那可能需要失效整个ID列表缓存。 - 性能高效:分页逻辑在内存中完成,速度快,批量获取数据(
MGET)减少了网络往返时间。 - 资源节省:相比于缓存每一页的完整数据,这种方案避免了数据冗余,一个商品详情只在
goods:detail:{id}中存一份,所有分页列表都共享这一份数据。
处理大结果集和深度分页

即使用了Redis,如果缓存起来的ID列表本身非常巨大(比如几十万条),虽然LRANGE操作本身很快,但序列化传输这个列表的一部分数据也可能成为瓶颈,对于超大的分页,比如第1000页,其实很少有用户真的会翻到底。
一种常见的优化是限制可翻页的深度,比如只允许用户往前翻100页,超过100页就需要更精确的搜索条件,另一种更高级的方案是使用游标(cursor)分页,类似于微博、抖音那种“下拉加载更多”的方式,它记录的是最后一条记录的位置,而不是页码,非常适合流式加载和超大数据集,但这又是另一个话题了。
总结一下
让数据查询快起来,用Redis缓存分页,核心诀窍就是:别直接缓存成品页,要缓存原材料,然后在Redis这个高速车间里进行分页组装,具体就是“ID列表 + 对象哈希”的组合拳,先通过一个List或Sorted Set缓存满足条件的所有数据ID,实现快速分页定位;再通过一个大的Hash或者多个String键来缓存每个对象的详细信息,实现批量快速获取。
没有银弹,具体业务具体分析,如果你的数据更新极其频繁,或者对实时性要求极高,可能就需要更复杂的缓存失效策略,甚至考虑不用缓存,但对于绝大多数读多写少的常规分页场景,上面这个方案经过无数项目的检验,确实能实实在在地让数据查询“飞”起来。 结束)
本文由盘雅霜于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/74916.html