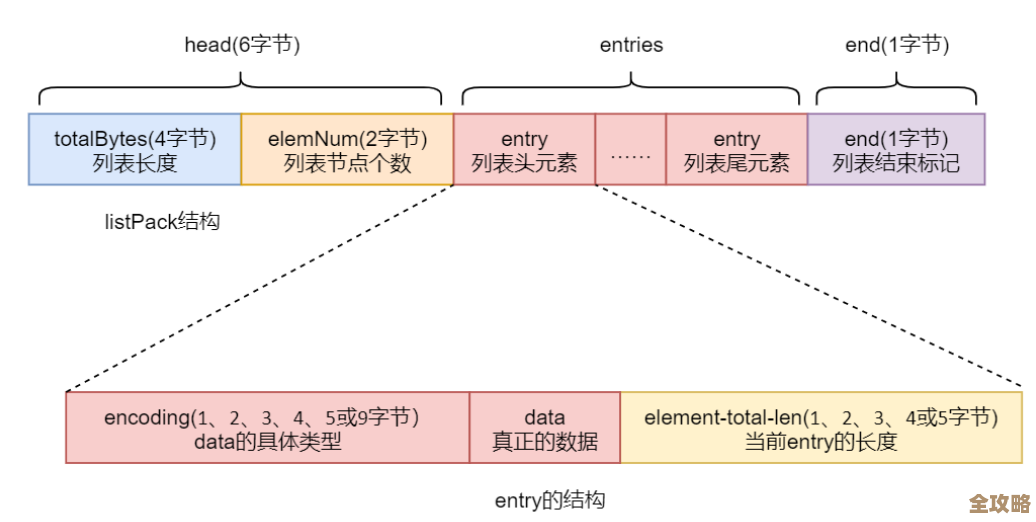
Redis里头怎么快点找到Key,查找技巧分享和实用方法解析

最重要的一点是,Redis本身并不像关系型数据库那样,有一个直接的、高效的“模糊查询”命令来遍历所有Key,像 KEYS 这样的命令,虽然可以用通配符(KEYS user:*)来查找,但它会一次性遍历整个Key空间,如果你的Redis里存了几百万甚至上亿个Key,使用 KEYS 命令简直就是一场灾难,它会严重阻塞服务器,导致其他所有请求都无法处理,所以在生产环境下是绝对禁止使用的。
既然不能暴力搜索,我们该怎么办呢?核心思路就两个字:规划,也就是在把数据存进Redis之前,就要想好以后该怎么找它,下面分享几种实用又高效的方法。
使用 SCAN 命令替代 KEYS(来源:Redis官方文档)
这是最基本也是必须掌握的技巧。SCAN 命令是 KEYS 的安全替代品,它也是迭代整个Key空间,但它是分批次进行的,每次只返回一小部分Key和一个游标(cursor),你拿到游标后,再下一次调用,直到游标返回0,表示迭代完成。
举个例子,你想找出所有以 product:123: 开头的Key:
SCAN 0 MATCH product:123:* COUNT 100这里的 0 是起始游标,MATCH 后面是匹配模式,和 KEYS 一样,COUNT 是建议每次返回的Key数量(注意,只是个建议,返回的数量可能比这个多或少)。
好处是什么? 因为 SCAN 是分次的,每次执行只占用很少的CPU时间,不会长时间阻塞Redis服务器,你可以在线上环境放心使用,它的缺点是在迭代过程中,如果Key有增加或删除,可能会遇到重复或丢失的情况,但对于大多数统计和查找场景来说,是可以接受的。
善用Key的命名规范(来源:Redis设计与实践的最佳实践)
这是最有效、也是最能体现“事前规划”的方法,给你的Key设计一个有规律的、清晰的命名结构,这就像给你的文件柜贴上详细的标签,而不是把文件胡乱塞进去。

常见的命名模式是 对象类型:ID:字段。
user:1001:name存储用户1001的名字。order:20231027:8888存储2023年10月27日的ID为8888的订单。product:book:5555存储分类为“图书”的ID为5555的商品。
这样做的好处是,当你需要使用 SCAN 命令时,你的匹配模式可以非常精确,比如你只想找用户1001的所有信息,你可以用 SCAN 0 MATCH user:1001:*,这样就极大地缩小了扫描范围,清晰的命名本身就是最好的索引。
利用数据结构充当“索引”(来源:常见的Redis应用模式)
这是更高级一点的技巧,但非常强大,既然Redis不允许我们直接给Key建索引,那我们就自己用Redis的数据结构来模拟一个“索引簿”。
场景1:按标签查找文章
假设你有很多文章,Key是 article:1, article:2... 每篇文章有多个标签,科技”、“Redis”、“数据库”,你可以这样做:

- 存储文章本身:
SET article:1 "{...文章内容...}" - 为每个标签维护一个集合(Set):
- 往
tag:科技这个集合里添加文章ID:SADD tag:科技 1 - 往
tag:Redis这个集合里添加文章ID:SADD tag:Redis 1 - 往
tag:数据库这个集合里添加文章ID:SADD tag:数据库 1
- 往
如果你想找所有带有“科技”和“Redis”标签的文章,只需要一个命令:
SINTER tag:科技 tag:Redis
这个命令会返回两个集合的交集,即同时拥有这两个标签的文章ID [1],这个过程非常快,是O(N)的复杂度,远比扫描所有Key要高效得多。
场景2:维护一个已知Key的列表
对于一些重要的、需要经常遍历的Key集合,你可以专门用一个Set或List来存下它们的全量Key。
所有在线用户的Key是 online:user:1001,那么你可以同时维护一个叫 online:users 的Set,每当一个用户上线,你就 SADD online:users 1001,下线就 SREM online:users 1001,这样,当你需要获取所有在线用户时,直接 SMEMBERS online:users 或者用 SSCAN 遍历这个集合就行了,这个集合的大小通常远小于整个数据库的Key总量。
通过工具辅助查找(来源:Redis运维经验)
除了在Redis内部想办法,也可以借助外部工具。
- Redis Desktop Manager等图形化工具:这些工具在界面上执行Key搜索时,底层通常也是使用的
SCAN命令,但提供了更友好的展示方式,适合在开发或测试环境使用。 - 编写脚本:你可以写一个简单的Shell脚本或Python脚本,使用
SCAN命令循环遍历,并将结果保存到文件里,或者进行更复杂的处理,这给了你更大的灵活性。
在Redis里快速找Key,诀窍不在于一个神奇的“查找”按钮,而在于良好的数据设计习惯。
- 绝对禁止在生产环境使用
KEYS命令。 - 首要选择是使用非阻塞的
SCAN命令进行扫描。 - 最有效的方法是建立清晰、有层次的Key命名规范,从源头上减少模糊查询的需要。
- 高级技巧是利用Set、Sorted Set等数据结构自己构建“二级索引”,通过集合运算来精准定位,这是效率最高的方式。
- 辅助手段是借助图形化工具或自定义脚本,让查找过程更便捷。
在Redis的世界里,速度是靠“设计”出来的,而不是“查”出来的。
本文由酒紫萱于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/74895.html