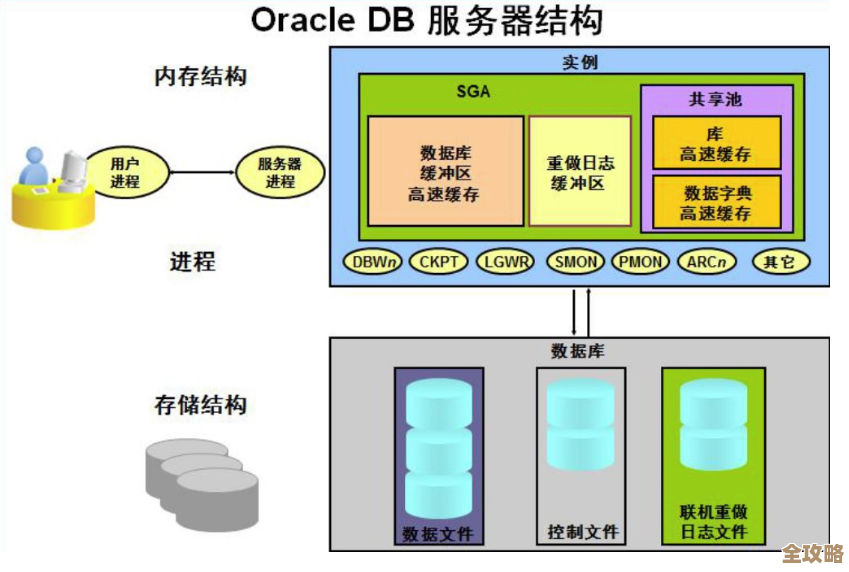
SQL Server索引到底怎么用才算对,别光建了不管效率反而差

很多人对数据库索引有个很大的误解,以为只要给表建了索引,查询就一定会变快,这其实是非常危险的想法,索引就像是一本字典的目录,用对了能让你快速找到想要的字,但如果你乱建目录,或者查字典的方法不对,反而会比一页一页翻更慢,SQL Server的索引也是如此,建了不管,或者建得不对,效率反而会急剧下降。
索引不是越多越好,关键在于“对”
首先必须明确一点:索引不是免费的午餐,每创建一个索引,都需要占用额外的存储空间,更重要的是,每当你在表中插入、更新或删除一条数据时,数据库不仅要修改表本身,还要去更新所有相关的索引来保持同步,这意味着,索引越多,写操作(增删改)的负担就越重,速度就越慢。
索引建设的核心原则是:按需创建,精准打击。 你的目标不是给每个列都建上索引,而是为那些真正影响查询性能的关键查询语句创建最有效的索引。
怎么判断哪些查询需要建索引?

你不能靠猜,必须依靠工具来发现性能瓶颈,SQL Server 提供了最直接的武器:执行计划。
当你在SQL Server Management Studio (SSMS) 里,选中一条查询语句,然后点击“显示估计的执行计划”(或按Ctrl+L),你会看到一个图形化的界面,这里面藏着所有秘密,你要重点关注的是那些有巨大百分比的步骤,特别是:
- 表扫描(Table Scan):这意味着数据库为了完成你的查询,不得不读取整个表的所有数据行,这是最糟糕的情况,通常发生在完全没有索引或者索引无法被使用的时候,就像你要找字典里一个“啊”字,却不得不从第一页翻到最后一页。
- 索引扫描(Index Scan):这比表扫描好一点,因为它是在读整个索引页,而不是整个数据页,但本质上还是扫描了大部分数据,效率不高,好比你知道“啊”字在字典拼音目录部分,但你还是把A开头的所有字都看了一遍。
- 索引查找(Index Seek):这是最理想的状态!数据库直接利用索引的B树结构,精确定位到你需要的那几条数据的位置,然后直接去拿,就像通过拼音目录直接翻到“a”所在的准确页码。
你的目标,就是通过创建合适的索引,让执行计划中的“扫描”尽可能变成“查找”。
建什么样的索引才算“对”?

发现了慢查询,也知道了是扫描导致的,那具体建什么索引呢?这里有几个关键点:
-
首选复合索引,而不是单列索引:如果您的查询条件经常是多个列一起出现(
WHERE city='北京' AND age>30),那么创建一个包含(city, age)的复合索引,远比单独为city和age各建一个索引要高效得多,复合索引的列顺序至关重要,应该把最常用于查询条件、选择性最高(即唯一值最多的)的列放在最前面。 -
理解“书签查找”的利与弊:索引查找虽然快,但它通常只包含了索引列的数据,如果你的查询需要返回的列(SELECT后面的列)超出了索引包含的范围,数据库就必须根据索引找到的主键,再回到原始数据表里去把其他列的数据取出来,这个“回表”操作就叫键查找(Key Lookup)或书签查找(RID Lookup),如果通过索引查找后,还需要回表成千上万次,这个成本会非常高,有时优化器甚至会放弃索引查找,直接选择扫描整个表。
解决方案是“覆盖索引”:如果你有一个非常核心的慢查询,可以尝试创建一个覆盖索引,即把你查询中所有需要用到的列(包括SELECT列表和WHERE条件中的列)都包含在索引中,这样,数据库只需要访问索引就能拿到全部数据,彻底避免了昂贵的书签查找,性能提升会非常显著,但切记,覆盖索引的代价是索引会更大,影响写性能,所以只适用于针对性的优化。

-
警惕索引碎片:索引建好了不是一劳永逸的,随着数据的不断增删改,索引页会变得支离破碎,就像一本被反复撕掉又贴上页面的字典,目录和内容都乱了套,这就是索引碎片,高碎片化的索引会导致数据库需要读取更多的磁盘页才能找到数据,严重拖慢查询速度。
定期维护是必须的:你需要定期(比如每周或每月,根据数据变动频率决定)检查并重建或重新组织索引,在SSMS中,可以右键点击索引,选择“重新组织”(针对轻度碎片)或“重建”(针对重度碎片),也可以编写自动化脚本来完成这个工作。
一些常见的索引使用陷阱
- 在索引列上使用函数或计算:
WHERE YEAR(createTime) = 2023,即使createTime列上有索引,这个索引也无法被使用,因为数据库需要对每一行的createTime值都计算一次YEAR()函数,正确的写法应该是WHERE createTime >= '2023-01-01' AND createTime < '2024-01-01'。 - 不恰当的通配符查询:
LIKE '%关键字%'这种前缀模糊查询,是无法使用索引的,会导致全表扫描,如果业务允许,尽量使用LIKE '关键字%'这样的后置通配符,这样索引仍然可以发挥作用。 - 数据类型不匹配:如果WHERE条件中,索引列的数据类型和传入的值类型不一致,SQL Server可能需要进行隐式转换,这也会导致索引失效,比如索引列是字符串类型
VARCHAR,你却用数字去查WHERE user_id = 123,数据库可能无法使用user_id上的索引。
想让SQL Server索引用得对,不是简单地“建”就完了,而是一个持续的“管”的过程,核心步骤是:先用执行计划找到慢查询 -> 分析慢的原因是扫描还是书签查找 -> 针对性地创建或调整索引(优先复合索引,必要时用覆盖索引) -> 定期维护索引以消除碎片。 要时刻注意避免那些让索引失效的写法,索引才能真正成为提升性能的利器,而不是拖垮系统的累赘。 综合自微软官方文档、Brent Ozar等业界专家的实践建议以及常见的DBA运维经验)
本文由歧云亭于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/74000.html