Redis底层是咋回事儿,内核那些原理和机制大概聊聊

Redis之所以这么快,感觉像闪电一样,根本原因在于它的设计者聪明地避开了传统数据库的很多慢操作,把力气都用在了刀刃上,咱们就聊聊它内核里的那些“小心思”。

Redis最核心的一点是,它把所有数据都放在内存里操作(来源:Redis官方文档),你想啊,读写硬盘的速度跟读写内存的速度比起来,就像是高铁和自行车的区别,数据在内存里,省去了慢吞吞的磁盘I/O,这是它快的基础,你可能会问,那断电了数据不就没了吗?Redis有办法,它可以用一种叫“持久化”的机制,隔一段时间把内存里的数据拍个快照存到硬盘上,或者把所有写命令记个日志,这样即使重启也能恢复数据,但这属于后台操作,不影响前台的高速服务。

光有内存还不够,怎么组织这些数据也是个大学问,Redis的键值对,并不是随便扔在内存里的,而是用一个巨大的哈希表来管理(来源:《Redis设计与实现》),你可以把这个哈希表想象成一个有无数个抽屉的柜子,当你要找一个叫“user:1001”的键时,Redis会用一个快速的算法(哈希函数)立刻算出这个键应该放在哪个抽屉里,然后直接去拉开那个抽屉拿东西,这个过程几乎是瞬间完成的,跟你去第一个抽屉还是第999个抽屉花的时间差不多,所以查找速度极快,不会因为数据多了就变慢。

接下来是数据类型的魔法,Redis不只是简单的字符串存储,它还有列表、集合、有序集合等等,这些类型的实现方式也很讲究。
- 字符串(String):最简单的类型,就是键对应一个值。
- 列表(List):它底层用的是一种叫“快速链表”的结构(来源:Redis源码注释),简单说,就是当列表元素少的时候,它用一块连续的内存来存储,这样很紧凑;当元素变多了,就变成由多个小内存块连接起来的链表,这样在中间插入数据时就不用挪动后面所有的数据,提升了效率。
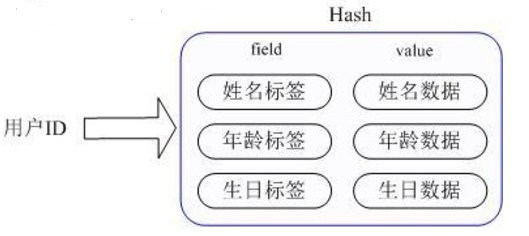
- 哈希(Hash):当字段数量少时,它用一种类似数组的紧凑方式来存储,省内存;字段多了,就自动升级成真正的哈希表,保证查询速度。
- 集合(Set):它底层也是哈希表,但只存键不存值,这样就天然保证了元素的唯一性,检查一个元素在不在集合里的操作非常快。
- 有序集合(ZSet):这是最精妙的结构之一,它同时用了两种数据结构:一个叫“跳跃表”(来源:《Redis设计与实现》),一个叫哈希表,跳跃表可以让你快速地按分数排序进行范围查询(比如取前十名),而哈希表则用于快速根据成员名查找对应的分数(比如查小红的分数),两种结构各司其职,用空间换来了无与伦比的速度。
然后就是处理网络请求的模式,Redis是单线程的(指处理命令的核心模块,新版本在某些地方引入了多线程,但核心逻辑还是单线程),你可能觉得奇怪,现在都多核时代了,为啥还用单线程?这不是自废武功吗?恰恰相反,这成了Redis的一大优势,单线程意味着它不用为线程切换、锁竞争这些复杂问题而烦恼(来源:Redis作者Antirez的博客观点),它用一个叫“I/O多路复用”的技术(来源:Unix网络编程模型),像是一个高效的门卫,这个门卫同时盯着很多个来自客户端的网络连接,当哪个连接有请求来了,门卫就通知Redis核心 worker去处理,因为所有数据都在内存里,每个命令的执行速度都极快,所以这个单线程worker完全忙得过来,反而避免了多线程带来的复杂性和开销,保证了每个操作的原子性,不会出现数据错乱。
当内存不够用时,Redis有淘汰机制,它会根据你设定的规则(比如LRU,最近最少使用),自动把一些不常用的数据从内存里删掉,给新数据腾地方。
Redis的快是多种设计选择叠加的效果:内存存储是基石,高效的数据结构是利器,单线程配合I/O多路复用避免了内部损耗,它就像一个极其专注的超级收银员,只负责结账这一件事,并且把商品都放在手边最顺手的位置,所以速度无人能及。
本文由邝冷亦于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73987.html