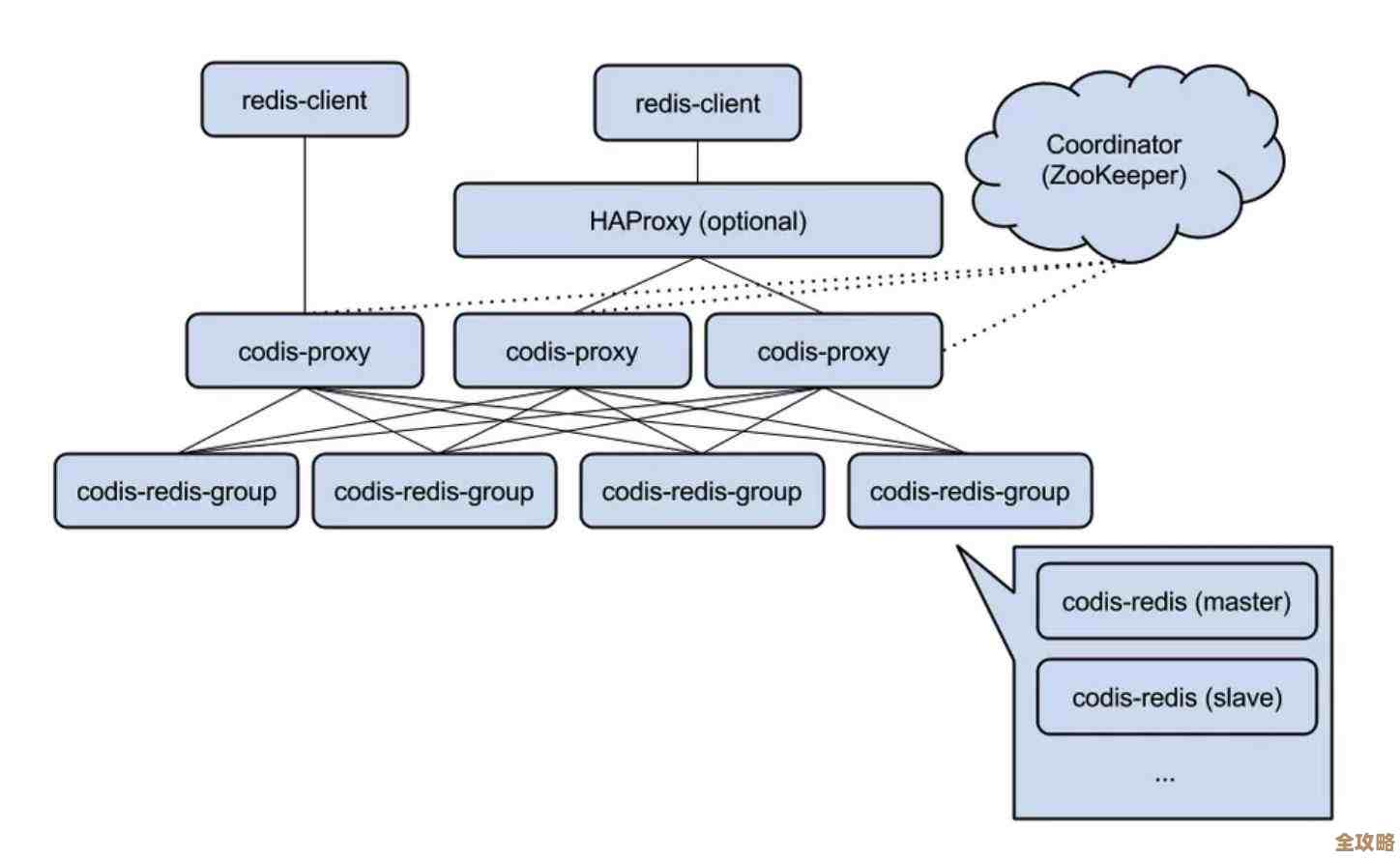
怎么才能快点把数据库还原好,省时间又不出错的那些方法分享

最重要的一点是,“快”不是指还原操作本身那几分钟,而是指从发现问题到业务完全恢复的整个周期时间。 很多团队只盯着还原命令的执行速度,却忽略了更耗时的准备工作、决策过程和验证环节,省时间又不出错的关键在于“准备”和“流程”。
准备工作做在平时:磨刀不误砍柴工
这是最核心的部分,如果平时没准备,出事时只能干着急。
-
制定清晰、定期测试的备份策略 根据“墨菲定律”,备份一定要在你最需要它的时候出问题,所以不能只满足于有备份,要确保备份是有效的。
- 定期恢复演练:就像消防演习一样,定期(比如每季度或每半年)找一个非核心的业务系统,真正去做一次从备份文件到恢复上线的完整流程,这会暴露出很多问题:比如备份文件是否损坏、恢复文档是否过时、操作人员是否熟练,根据“CSDN技术社区”多位网友的分享,很多重大事故都是因为长期不验证备份,真到用时才发现备份无效。
- 明确备份类型和保留周期:你需要知道有什么样的备份,有每天一次的“全量备份”(备份整个数据库),还有每隔几小时一次的“增量备份”(只备份上次以来的变化),要清楚这些备份文件都放在哪里,保留了多久,这样在需要还原到某个特定时间点时,你才能快速找到正确的文件。
-
准备好“恢复手册”和“应急预案” 事故发生时,人容易紧张,大脑会一片空白,绝对不能靠记忆操作。
- 详细的步骤文档:把还原操作的每一步命令、每一个参数、每一步检查点都写成文档,这个文档要简单到让一个不太熟悉的人也能照着做,文档必须随时更新,当数据库版本或环境变化时,要及时修订。
- 明确的沟通预案:出了问题,先通知谁?业务部门谁来做决策?是恢复到最后一次备份的点,还是需要尝试恢复更多数据?这些决策流程要提前定好,根据“知乎上某位DBA的实践经验”,混乱的沟通和权责不清是导致恢复时间延长的主要原因之一。
还原过程中的效率技巧
当真的需要还原时,以下方法可以帮你节省时间。
-
选择合适的恢复目标 很多时候,我们并不需要把数据库恢复到出问题前的最后一秒,如果是下午4点发现数据被误删了,但最后一次完整备份是凌晨2点,你可以先尝试恢复到凌晨2点的状态,这通常是最快最稳的,再根据业务重要性,决定是否要应用后续的日志备份,将数据追到比如下午3点50分(假设误操作发生在3点55分),这个决策能大大缩短恢复时间。
-
先在小范围验证 这是一个非常有效的“防出错”技巧,如果条件允许,不要直接在生产环境上操作。
- 搭建镜像测试环境:先在一台和生产线配置差不多的测试服务器上,用备份文件进行还原,这样做有两个巨大好处:第一,可以验证备份文件本身是好的;第二,你可以精确计算出整个还原过程需要多长时间,为生产环境的恢复提供准确的时间预期,方便通知业务方,很多“腾讯云数据库最佳实践”文章中都强调过“先验后产”的重要性。
-
优化还原操作的具体动作
- 确保硬件资源充足:还原数据库是个重体力活,非常消耗CPU、内存和磁盘读写速度,如果可能,临时关闭一些不必要的应用程序,为还原任务让出资源,特别是磁盘,确保备份文件放在读写速度最快的硬盘上。
- 利用工具和脚本:如果你经常需要做类似操作,可以把复杂的还原命令写成脚本,一键执行脚本远比手动输入一长串命令快,而且不容易输错,但切记,脚本也要定期测试。
恢复后的收尾工作同样重要
数据还原成功,数据库服务启动,这并不算完。
-
必须进行数据验证 还原后,不能直接告诉业务方“好了,你们用吧”,需要快速进行一些核心校验,检查最重要的几张数据表的总行数是否正常;登录几个关键用户的账号,看看基本信息是否正确;跑一个核心报表,看看数据是否对得上,这个验证过程可能只需要十几分钟,但能避免“数据恢复错了”这种灾难性的二次事故。
-
记录和分析事故原因 所有事情处理完毕后,一定要开一个复盘会,这次问题是怎么发生的?是人为误操作?是程序bug?还是系统故障?根据“阿里巴巴开发手册”倡导的理念,复盘不是为了追究责任,而是为了从根本上解决问题,制定措施防止未来再次发生同样的问题,这可能比优化还原流程本身更有价值。
想要又快又好地还原数据库,核心思想是:将大部分工作前置到平时的准备和演练中,事中严格遵循预案和流程,事后做好验证和复盘。 你的镇定自若,源于你胸有成竹的准备。

本文由盘雅霜于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73790.html