Redis线程死锁问题剖析,聊聊那些让人头疼的死锁情况和解决思路

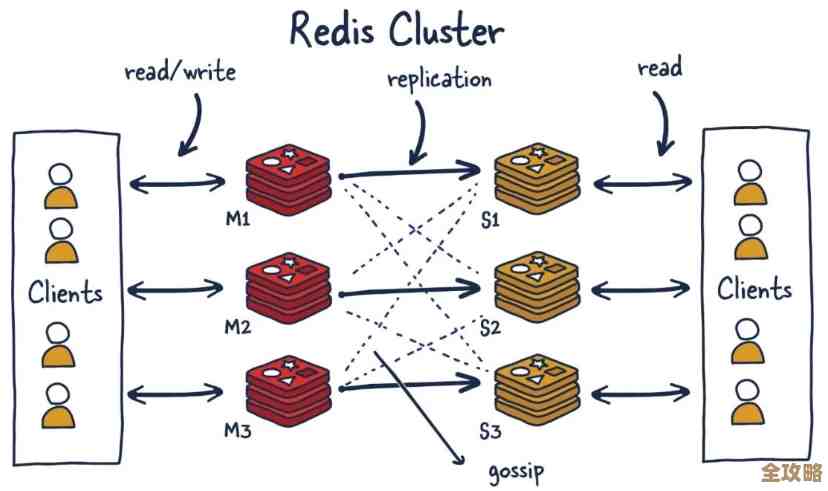
关于Redis线程死锁的问题,其实是一个让很多开发者感到困惑的话题,因为大家通常听说Redis是单线程的,怎么还会出现“死锁”呢?这里需要澄清一下,我们讨论的“死锁”并不是传统多线程编程中,两个线程互相等待对方释放锁的那种死锁,Redis核心网络模型确实是单线程处理命令的,所以不存在这种内部竞争,我们说的“死锁”,是指客户端逻辑上的阻塞和资源无法访问的现象,其表现和后果与传统死锁非常相似,都会导致系统部分或全部功能卡住。
根据一些技术社区像知乎、掘金上的讨论和Redis官方文档的说明,常见的让人头疼的“死锁”情况主要有以下几种:
第一种情况:不合理的慢查询阻塞了整个服务。 这是最常见也最危险的“单点死锁”,因为Redis的工作线程只有一个,它就像一个唯一的收银员,如果某个客户端发来一个非常耗时的命令,比如对一个包含几百万个元素的集合执行KEYS *操作,或者一个复杂的Lua脚本执行时间过长(根据Redis Labs官方博客的说明,Lua脚本在执行期间是原子性的,会阻塞其他所有命令),这个“收银员”就得花好几分钟甚至更长时间来处理这一个“顾客”,结果就是后面所有的“顾客”(其他客户端的请求)全都得干等着,整个Redis服务对外表现为不可用,这相当于这个慢查询命令“锁住”了Redis唯一的服务线程。
第二种情况:客户端自己造成的逻辑死锁。 这种场景在分布式锁的使用中特别典型,客户端A使用SETNX命令成功获取了一个锁,并设置了超时时间(比如10秒),然后客户端A开始执行一段业务逻辑,如果这段业务逻辑的执行时间超过了10秒,那么Redis中的这个锁会因为超时而被自动释放,客户端B就能成功获取到同一个锁,紧接着,客户端A的漫长业务终于执行完了,它开始执行释放锁的代码,如果释放锁的逻辑没有做校验,它就会把本来属于客户端B的锁给释放掉,这就乱套了,更糟糕的是,如果客户端A的业务逻辑中,在释放锁之前,又需要去申请另一个资源,而这个资源可能正被客户端B持有,这就形成了典型的跨进程、跨客户端的死锁循环等待。

第三种情况:资源竞争导致的活锁。 这种情况在大量客户端同时争抢同一个锁时会发生,一个热门商品秒杀,瞬间有上万个请求来争抢库存锁,当锁被释放的瞬间,所有客户端都同时去尝试获取锁(例如使用SETNX),最终只有一个客户端能成功,其他上万个客户端都失败,然后这些失败的客户端通常会立即重试,这就导致Redis要瞬间处理海量的SETNX命令,虽然每个命令都很快,但巨大的网络IO和CPU压力可能会让Redis性能骤降,使得获取锁和释放锁的过程变得异常缓慢,从客户端角度看,感觉就是锁系统卡顿了,虽然没完全死掉,但谁也正常不了,类似于一种“活锁”。
面对这些头疼的问题,有什么解决思路呢?

对于慢查询阻塞,核心思路是“防患于未然”,首先要通过slowlog命令持续监控慢查询,找出并优化那些耗时的命令,比如用SCAN替代KEYS,优化Lua脚本,要给命令设置合理的超时时间,必要时在客户端做熔断降级,避免一个慢请求拖垮整个应用。
对于客户端逻辑死锁,关键在于“规范使用分布式锁”,一个成熟的分布式锁方案应该至少包含以下几点:1)设置一个唯一的客户端标识(如UUID)作为锁的值,在释放锁时校验这个标识,确保只能释放自己加的锁,2)设置一个合理的锁超时时间,这个时间要大于业务逻辑的平均执行时间,避免业务没做完锁就超时,3)如果业务执行时间不确定,可以考虑使用看门狗机制(watchdog)来定期续期锁,确保业务完成前锁不会过期。
对于资源竞争活锁,解决方法是“减少竞争和引入随机性”,可以采用令牌桶等限流机制,在客户端层面控制请求Redis的频率,避免洪水般的重试请求,在获取锁失败后,不要立即重试,而是采用一种带有随机延迟的退避策略(比如指数退避),让客户端的重试时间分散开,减轻Redis的压力。
理解Redis“死锁”的本质是解决问题的第一步,它提醒我们,即使像Redis这样简单的组件,如果使用不当,尤其是在分布式环境下,同样会引发严重的可用性问题,关键在于良好的编程习惯、对Redis特性的深入理解以及完善的监控预警机制。
本文由畅苗于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73667.html