Redis怎么用在数据库设计里,设计思路和那些常见的模式分享

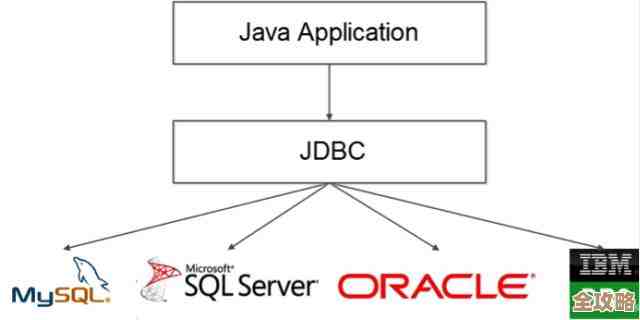
Redis在数据库设计里,主要不是用来替代像MySQL、PostgreSQL这类传统的关系型数据库,而是作为它们的强力补充,你可以把它想象成电脑的CPU缓存和内存条,它们速度极快,但容量有限且断电后数据会消失(除非配置为持久化);而传统数据库就像是硬盘,容量大,能永久保存数据,但速度相对慢很多,设计思路的核心就是“扬长避短”,把Redis的速度优势和传统数据库的持久化优势结合起来。
这个核心思路引出了一个非常重要的设计模式,叫做缓存模式,这是Redis最常用、最基础的模式,它的逻辑很简单:当应用程序需要读取数据时,首先飞速地去Redis里查一下有没有这个数据,如果有(这被称为“缓存命中”),就直接返回结果,完全不用去麻烦速度慢的数据库,如果Redis里没有(这被称为“缓存未命中”),再去数据库查询,拿到数据后,不仅返回给应用程序,还会在Redis里也存一份,并且设置一个过期时间,这样下一次同样的请求过来,就能直接从Redis中快速获取了。
使用缓存模式会遇到几个经典问题,解决这些问题的办法也成了常见的子模式,第一个问题是缓存穿透,想象一下,如果有人一直请求一个根本不存在的数据,比如查询一个不存在的用户ID,每次请求都会穿透Redis,直接打到数据库上,相当于缓存失效了,会给数据库带来巨大压力,解决办法是,即使从数据库没查到数据,也在Redis里存一个空值(比如null),并设置一个很短的过期时间,这样短时间内再来请求这个不存在的数据,就会命中Redis里的空值,从而保护数据库。
第二个问题是缓存雪崩,假设Redis里大量缓存数据在同一时间点过期,那么这一刻所有对这些数据的请求都会同时涌向数据库,数据库可能瞬间就被压垮了,就像雪崩一样,解决办法很简单,就是给缓存数据的过期时间加上一个随机值,让它们分散开失效,避免集体失效的灾难性后果。
第三个问题是缓存击穿,这个和雪崩有点像,但针对的是某一个非常热点的数据,比如一个明星爆出新闻,他的微博信息是热点数据,如果这个热点数据突然过期了,此时海量的请求都会发现缓存失效,然后同时去数据库查询这个热点数据,数据库可能瞬间就被这一个查询打垮,解决办法通常是用“锁”的机制,只允许一个请求去数据库查询并重建缓存,其他请求等待缓存重建完成后直接读取新缓存。

除了作为缓存,Redis凭借其丰富的数据结构,还能实现很多更高级的用法,这些也是常见的数据库设计模式。
一种是计数器模式,在社交网站上,文章的点赞数、评论数、转发数需要频繁更新,如果每次点赞都直接去数据库执行UPDATE table SET likes = likes + 1,数据库的写入压力会非常大,这时可以用Redis的INCR命令,先在内存里快速完成计数,然后再定时或者在数量变化达到一定阈值时,将最终结果同步回数据库,这样就把成千上万次的数据库写操作,变成了Redis内存的快速操作和少量数据库写操作。
另一种是排行榜模式,Redis有一个叫有序集合的数据结构,它能自动根据一个分数来排序,这个特性天生就是为排行榜设计的,比如游戏里的玩家积分榜,每次玩家得分变化,只需要用ZADD命令更新一下他在有序集合里的分数,Redis会自动维护好排名,查询top 10的玩家就是一条ZREVRANGE命令的事情,速度极快,完全避免了在关系型数据库里用ORDER BY和LIMIT进行大量计算和排序的开销。

还有一种是会话存储模式,用户登录网站后,服务器会创建一个会话(Session)来记录用户的登录状态,如果把Session存在本机内存,当有多台服务器时,用户下次请求可能被分配到另一台机器,就找不到登录信息了,传统做法是弄一个专门的Session服务器或者存在数据库里,但速度都不够理想,Redis因为速度快、支持过期时间,而且是独立于应用服务器的中心化存储,就成了存储Session的绝佳选择,用户登录后,生成一个唯一ID作为key,用户信息作为value存入Redis,并将这个ID返回给用户的浏览器(存为Cookie),之后用户的每次请求都带着这个ID,服务器就能快速地从Redis中拿到用户的会话信息。
在处理一些需要快速读写和复杂操作的业务时,甚至会采用Redis作为主数据库的模式,比如一个实时聊天系统,消息的发送和读取要求毫秒级响应,并且要支持最近聊天记录查询、在线状态管理等,这些功能用Redis的列表、集合、哈希等结构可以非常高效地实现,这通常需要配合Redis的持久化功能(如AOF),来保证数据不会因为重启而全部丢失,适用于对数据一致性要求不是极端严格,但对性能要求极高的场景。
在数据库设计中引入Redis的思路,本质上是一种分层设计,根据数据的特点(是否频繁读写、是否要求极速响应、是否允许短暂延迟)来决定把它放在哪一层,通过缓存模式提升读取性能,通过特有的数据结构模式实现复杂业务逻辑,最终目的是构建一个既快又稳的系统。
(参考资料:这些设计思路和模式广泛存在于技术社区的实践分享中,例如在《Redis实战》(Josiah L. Carlson著)一书中对缓存模式和数据结构应用有详细阐述;马丁·福勒(Martin Fowler)在博客中曾探讨过缓存的相关模式;国内外的技术博客如阿里云开发者社区、Medium上的技术文章等,也经常讨论这些常见的Redis使用模式。)
本文由水靖荷于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73608.html