Redis怎么帮忙搞访问统计,效率能不能蹭蹭往上涨

Redis这玩意儿,说白了就是个超级快的“大内存哈希表”,它把数据都放在服务器的内存里,所以读写速度飞快,比去硬盘里翻数据库要快几个数量级,用它来搞访问统计,那效率绝对是蹭蹭往上涨,就像给自行车换上了火箭引擎,下面我具体说说它怎么帮忙,以及为啥能这么快。
Redis怎么帮忙搞访问统计?
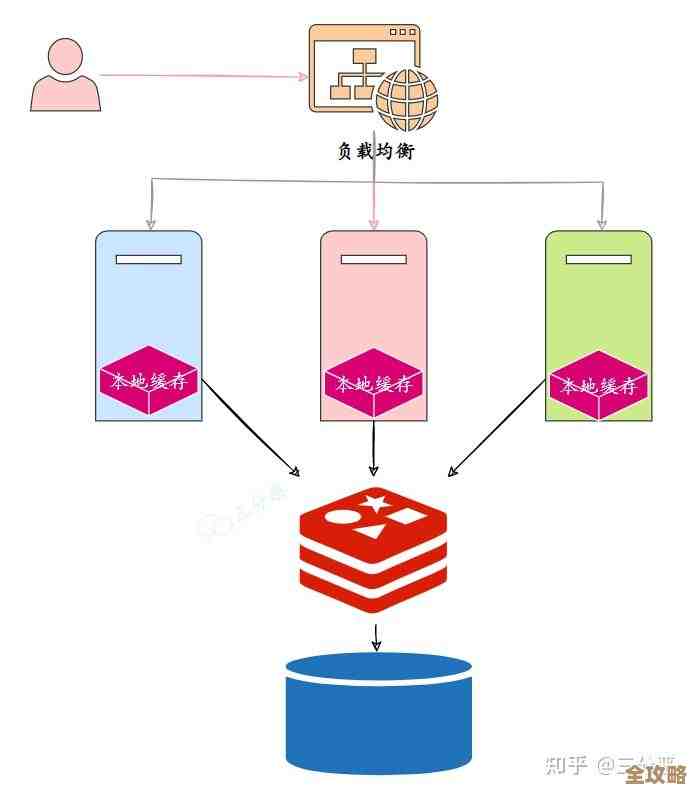
访问统计无非就是记录“谁在什么时候干了什么”,然后对这些记录进行汇总分析,传统做法是用户每访问一次,就往数据库(比如MySQL)里插一条记录,人少的时候还行,人一多,数据库就扛不住了,频繁的写入操作会成为瓶颈,网站可能就卡死了。
Redis解决这个问题的方法很“简单粗暴”,它利用自己超快的读写能力,先把海量的访问数据“吞”到肚子里(内存里),然后再找合适的时机,慢慢地“消化”(持久化到数据库)或者直接分析,具体可以这么玩:

-
实时计数,原子操作:这是Redis最经典的用法,比如要统计网站的总访问量(PV),或者一篇文章的阅读数,传统数据库的做法是:先查询当前的数值,然后加一,再写回去,这个过程中如果有两个人同时操作,可能会出错,Redis提供了
INCR这个命令,直接给某个键的值加一,这个操作是“原子性”的,意味着它又快又不会出错,你只需要在用户每次访问时,执行一下INCR article:123:page_view就行了,速度极快,根据Redis官方文档的描述,一个普通的服务器一秒钟处理几十万次这种简单命令跟玩儿似的。 -
处理唯一性统计:比如要统计一天内的独立访客数(UV),也就是去重后的访问人数,如果用数据库,你得对访问日志里的用户ID进行
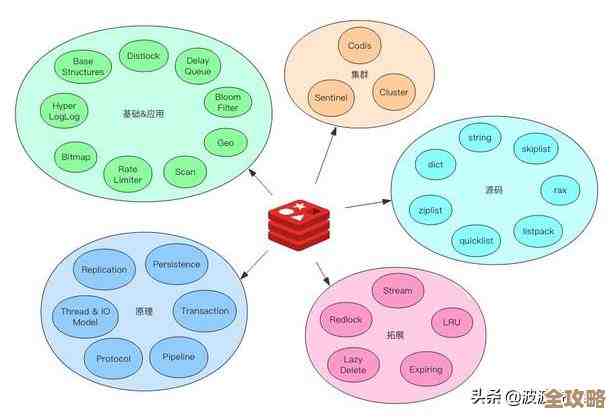
DISTINCT去重,数据量一大,查询慢得能让你怀疑人生,Redis有个数据结构叫HyperLogLog,它最大的优点就是占用的内存空间极小,并且只需要一个命令PFADD就能完成添加和去重,比如执行PFADD uv:20240517 "用户IP或ID",它可以帮你估算出独立用户数,虽然是个近似值,但误差率极低(不到1%),对于访问统计这种场景完全够用,但速度却比精确计算快成百上千倍,这个数据结构的设计原理在菲利普·杰沃德(Philippe Flajolet)等人的论文《HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm》中有详细阐述。 -
存储排行榜:很多网站有“今日热门文章”、“点击排行榜”之类的功能,如果用数据库,你得
GROUP BY再ORDER BY,实时计算的话数据库压力巨大,Redis的ZSET(有序集合)天生就是干这个的,每次有人点击文章,你就执行ZINCRBY hot_articles 1 article_id,给这篇文章的分值加一,查排行榜的时候,直接用ZREVRANGE hot_articles 0 9就能取出前十名,这个操作的时间复杂度是O(log(N)),速度快到可以忽略不计。 -
缓存聚合结果:对于一些不需要绝对实时的统计,过去一小时的活跃用户数”,我们可以利用Redis设置过期时间的特性,先在一小时内用
SET或LIST等结构把数据存起来,同时设置一小时的过期时间,等需要查询时,直接对Redis里的数据进行计算,或者干脆每分钟计算一次结果,然后把结果缓存起来,后续的请求直接读这个缓存结果,这样就把复杂的统计查询变成了简单的键值查找,效率自然飞起。
效率为啥能蹭蹭往上涨?
效率的提升不是一点半点,是质的飞跃,主要原因如下:
-
内存操作是王道:Redis的数据主要存储在内存中,内存的读写速度是纳秒级别的,而传统机械硬盘是毫秒级别的,差了十万倍,即使是固态硬盘(SSD),也远远赶不上内存的速度,这就决定了Redis的先天优势,根据计算机体系结构的基本原理,CPU访问L1缓存的速度大约是1纳秒,访问内存的速度大约是100纳秒,而访问SSD的速度则可能是100微秒(0.1毫秒),差距显而易见。
-
单线程模型避免锁竞争:Redis在处理命令时是单线程的(新版本在网络IO等地方用了多线程,但核心命令处理还是单线程),这听起来好像是缺点,但其实是它高性能的关键,它避免了多线程环境下复杂的锁竞争问题,不会因为线程切换而消耗资源,所有的命令都是顺序执行的,非常清爽,这使得Redis在应对海量并发请求时,依然能保持稳定的低延迟。

-
高效的数据结构:Redis不是简单地存字符串,它内置了哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)等多种数据结构,这些结构都是为特定场景高度优化的,比如前面提到的用
ZSET做排行榜,用HyperLogLog做基数统计,直接用现成的命令就能完成复杂操作,比自己写代码去数据库里折腾要高效得多。 -
异步持久化保证数据安全:你可能担心内存数据断电就没了,Redis提供了两种持久化机制(RDB快照和AOF日志),可以把内存数据备份到硬盘上,关键是,这个持久化过程通常是异步的,不会阻塞对外的读写服务,你可以理解为,Redis让一个“小弟”去负责慢速的硬盘备份工作,自己则专心致志、全力以赴地处理高速的内存读写请求。
总结一下:
用Redis搞访问统计,核心思路就是“前端高速写入,后端异步处理”,它像一个超级能干的“前台”,把所有瞬间涌来的访问记录都先接下来,记在小本本(内存)上,保证了网站的响应速度,再慢慢地把这些记录整理成册,归档到“档案室”(数据库)里,或者直接在小本本上做快速分析。
如果你的网站或应用访问量不小,想做实时或准实时的访问统计,引入Redis绝对是一个能让效率“蹭蹭往上涨”的明智选择,它用起来不复杂,但带来的性能提升是实实在在的。
本文由太叔访天于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73548.html