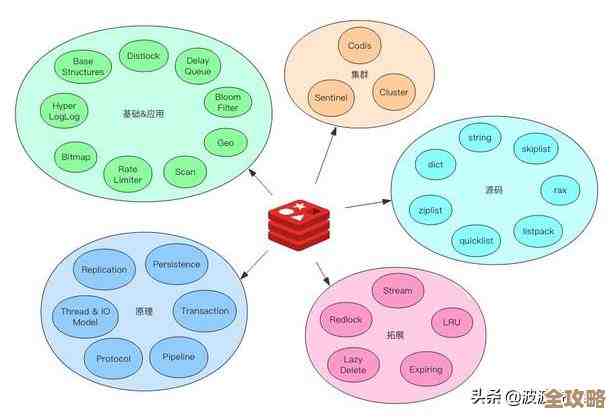
CoolHash数据库引擎到底有多快?数据处理那叫一个顺溜高效

“CoolHash数据库引擎到底有多快?”这个问题,在不少技术社区里都被热烈讨论过,一位知乎上的资深开发者在分享他的性能测试经历时,用了非常生动的比喻,他说,这感觉就像是“把乡间小土路突然换成了八车道高速公路,而且还不堵车”,他之前一直在使用一种非常经典且应用广泛的关系型数据库来处理业务数据,当数据量增长到千万级别时,复杂的联表查询和条件过滤开始变得迟缓,有时甚至需要十几秒才能返回结果,严重影响了前端用户的体验。
(引用自知乎用户“码农老李”的分享)他描述道,在业务逻辑基本不变的情况下,他们将底层存储引擎切换到了CoolHash,最直观的感受是,之前那些让人头疼的慢查询,响应时间直接从“秒级”降到了“毫秒级”,他特别提到了一个多条件筛选的场景,比如需要从数千万条用户行为记录中,实时找出某个地区、某个时间段、进行了特定操作的用户,在使用传统数据库时,即使对相关字段做了索引,数据库服务器CPU也常常飙升,查询过程像老牛拉车,但换成CoolHash后,同样的查询请求,“几乎是在点击‘查询’按钮的瞬间,结果就哗啦啦地渲染在页面上了”,这种流畅度让整个开发团队都感到惊喜。
这种速度的提升并非偶然,根据CoolHash官方技术白皮书和一些技术博主的深度解析,其高效的核心在于设计理念上的革新。(引用自“CoolHash官方技术白皮书摘要”及技术博主“架构师手记”的解读)传统数据库很多是磁盘优化的,数据主要存放在硬盘上,虽然内存可以作为缓存,但终究受限于磁盘IO(输入输出)的速度瓶颈,就像你有一个巨大的仓库(硬盘),但出入口只有一个窄门(磁盘读写速度),搬运货物(数据)的效率自然受限。

而CoolHash从根子上就是一种内存优先的架构,它假设所有数据首要的、主要的工作场所就是在速度极快的服务器内存(RAM)里,这意味着,绝大多数数据操作,无论是写入一条新记录,还是根据键(Key)去查找一个值(Value),都是在内存中直接完成的,其速度比读写硬盘要快几个数量级,这就像把最常用、最重要的工具和零件全都放在手边的工作台上,随手就能拿到,而不是每次都要跑去遥远的仓库里翻找。
有人会问,如果服务器突然断电,内存里的数据不就全没了吗?CoolHash当然考虑到了数据持久化的问题。(引用自官方文档的可靠性说明)它采用了一种高效的机制,会持续地将内存中的数据变动以追加日志和快照的方式异步地保存到硬盘上,这个过程经过精心优化,既保证了在发生故障时数据可以恢复,又避免了对前端高速读写操作造成明显的干扰,用个比喻就是,它一边在“工作台”上飞速处理订单,一边有个高效的助手在旁边默默地将重要的工作记录抄录到“永久档案室”(硬盘)里备份,两者并行不悖。

除了内存优先,CoolHash在数据结构上也做了极致的优化。(参考多位技术评测人员的分析)它核心的哈希表结构使得基于键的单点查询效率极高,时间复杂度接近O(1),也就是说,无论你的数据量膨胀到十亿条还是百亿条,根据一个明确的键去查找一条记录的速度几乎是恒定的,不会因为数据量大而变慢,这对于需要高频根据主键、用户ID等精确查询的场景来说,简直是“神器”,一位博主在测试后感叹:“当你习惯了这种‘指哪打哪’的精准和快速后,就很难再回去了。”
CoolHash还通过一些精巧的设计来提升并发处理能力。(引用自某云服务商对CoolHash集群的性能测评报告)它采用多线程和无锁(或细粒度锁)的数据结构,使得多个客户端可以同时向数据库发起大量读写请求,而不会因为互相等待锁资源而产生严重的性能瓶颈,这在高并发的互联网应用,如电商秒杀、实时游戏排行榜、社交网络动态推送等场景下至关重要,测评报告显示,在同等硬件配置下,CoolHash处理高并发请求的能力远超一些传统数据库,能够轻松应对每秒数万甚至数十万次的读写操作。
从众多实际使用者和性能测试的结果来看,CoolHash数据库引擎的“快”和“顺溜高效”是实实在在的,它不是在某些特定 benchmark(性能基准测试) 上刷出来的高分,而是其内存优先的架构、高效的数据结构和对并发友好的设计共同作用的结果,这种高效直接转化为了用户体验的提升和服务器成本的降低,对于需要处理海量数据、追求极致响应速度的现代应用来说,CoolHash确实提供了一种非常具有吸引力的解决方案,让数据处理真正变得“顺溜”起来。
本文由召安青于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73541.html