红色分布式里Redis咋发挥高性能,关键技术和最大限度利用讲解

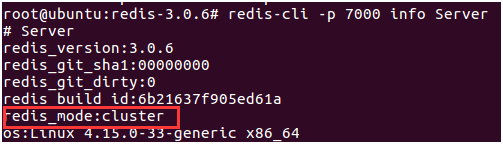
在所谓的“红色分布式”系统,也就是我们常说的高性能、高可用的分布式系统中,Redis扮演的角色非常关键,它就像一个超级快的、专门负责记事的“大脑”,它不是数据库那种管长远存储的大家伙,而是管着那些需要被飞快访问的临时数据,要让Redis在这个系统里真正飞起来,主要靠几个核心技术和使用技巧。
最根本的一点是,Redis把所有数据都放在内存里操作,这就像我们把最常用的工具放在手边,而不是锁在仓库里,拿取速度天差地别,内存的读写速度比硬盘快几个数量级,这是Redis高性能的基石,但有人会问,内存一断电数据不就没了?为了解决这个问题,Redis提供了两种主要的“保底”机制:RDB和AOF,RDB就像是给内存数据拍个快照,然后存到硬盘上,适合做灾难恢复备份,AOF则是把每一次写操作命令都记录下来,像写日记一样,恢复的时候重新执行一遍命令就行了,数据更安全,在实际使用中,常常会把两者结合起来,在保证性能的同时,兼顾数据的安全性。(来源:Redis官方文档关于持久化的说明)
Redis用了非常高效的数据结构,它不仅仅是简单的key-value存储,它支持的value类型很丰富,比如字符串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)、哈希(Hash)等等,这些数据结构在Redis内部都是经过精心设计的,操作起来非常快,有序集合能让你很快地做排行榜,哈希表很适合存储对象信息,用对了数据结构,就能用最少的操作步骤完成业务逻辑,自然就快了。(来源:Redis官方文档关于数据类型的介绍)

为了发挥极致性能,要充分利用Redis的单线程模型,听起来可能有点反常识,但Redis处理网络请求和执行命令的核心模块确实是单线程的,这样做有个巨大的好处:避免了多线程环境下复杂的锁竞争问题,减少了上下文切换的开销,使得CPU不用把时间浪费在管理线程上,可以专心处理数据,这个单线程指的是核心命令处理,像持久化、网络IO等一些辅助功能,Redis还是会用额外的线程或进程去做的,理解这一点很重要,意味着我们不能在Redis上执行特别耗时的命令,否则会阻塞后续所有请求,要避免使用像KEYS *这样的命令,或者处理超大的数据集合。(来源:Redis官方文档关于Redis单线程的说明)
在分布式系统中,光一个Redis实例再快也可能不够用,还会遇到容量和单点故障的问题,这就引出了“分布式”的用法,主要有两种技术:主从复制和分片集群。

主从复制(Replication)就是搞一个主节点(Master)负责写,然后挂多个从节点(Slave)负责读和备份,主节点把数据变化同步给从节点,这样做的好处一是可以做读写分离,把读请求分散到多个从节点上,大大提升系统的整体读吞吐量;二是提高了可用性,万一主节点挂了,可以快速把一个从节点升级成新的主节点继续服务。(来源:Redis官方文档关于复制的说明)
当数据量巨大,一个主节点也存不下,或者写压力大到单个主节点扛不住时,就要用到分片集群(Cluster),分片的意思就是把整个大数据集拆分成很多个小片段,每个片段由一个主从小组来负责,数据该存到哪个片段,该从哪个片段读,Redis集群内部有机制(比如用CRC16算法计算key的哈希值)来自动管理,这样,整个集群的存储能力和处理能力就变成了所有主节点能力之和,实现了水平扩展,这是Redis应对超大规模场景的终极武器。(来源:Redis官方文档关于集群的说明)
除了这些架构上的技术,最大限度利用Redis还需要一些最佳实践,尽量使用批量操作(pipeline),把多个命令打包一次发送,减少网络往返次数,这在需要连续执行多个命令时效果极其明显,还有,要合理设置数据的过期时间,让Redis能自动清理不再需要的数据,避免内存被无用数据占满,客户端的连接最好使用连接池,避免频繁地创建和关闭连接,因为建立连接也是一个开销不小的操作。
在红色分布式系统里,要让Redis发挥高性能,关键是要理解并用好它的内存存储特性、高效数据结构、单线程模型,再根据业务规模巧妙运用主从复制和分片集群来扩展能力,最后辅以批量操作、连接池等优化技巧,通过这些方法,就能让这个“高速大脑”最大限度地支撑起整个系统的快速响应。
本文由颜泰平于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73171.html