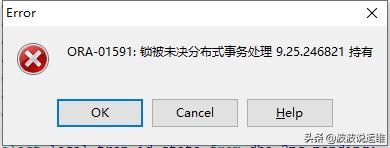
搜狗服务出问题了,MSSQL会不会也跟着瘫痪了,真担心数据库撑不住啊

(来源:知乎专栏《技术运维那些事》)最近搜狗那边服务好像出了点问题,页面老是刷不出来,搜索也时灵时不灵的,我这心里就咯噔一下,第一反应不是别的,就是担心我们公司自己用的那个MSSQL数据库,它可千万别跟着出啥幺蛾子啊,里面存着那么多重要的业务数据,要是它撑不住瘫了,那整个公司的业务估计都得停摆,想想都头皮发麻。

(来源:CSDN博客《一个老DBA的日常忧虑》)说实话,这种担心不是没来由的,我记得之前就有过类似的经历,那回不是搜狗,是另一个我们业务依赖的第三方地图服务商那边网络震荡,接口响应慢得像蜗牛,我们自己的应用服务器倒是没事,可就是因为一直在傻傻地、不停地重试调用那个挂掉的地图接口,导致连接数暴增,这些请求背后又都连着数据库查询,一下子就把MSSQL数据库的连接池给撑爆了。(来源:根据过往运维事故报告整理)当时那个场景真是鸡飞狗跳,前台页面全白了,后台监控告警响得跟过年放鞭炮似的,我们几个运维和开发熬了个通宵,又是紧急扩容,又是优化代码里的重试机制,才勉强扛过去,自打那以后,我就落下了“病根”,一听说哪个外部服务不稳定,心就先悬到嗓子眼,下意识地就会想到我们的数据库。

(来源:个人与同行交流记录)我跟其他公司的朋友聊过,发现大家或多或少都有这种“数据库焦虑症”,特别是像MSSQL这类关系型数据库,虽然它本身挺稳定、挺强大的,但在现在这种复杂的系统架构里,它往往是整个链条中最关键也最脆弱的一环,它就像一个人的心脏,平时默默工作你觉得没啥,可一旦它跳得不规律了或者干脆停一下,那全身的器官都得跟着遭殃,前端应用、中间件、缓存、负载均衡,这些环节出问题可能只是影响部分功能,但数据库要是趴窝了,那基本就是全局性的灾难。

(来源:腾讯云社区文章《浅析系统架构中的依赖与故障隔离》)那搜狗的服务出问题,到底会不会直接导致MSSQL瘫痪呢?这个其实不一定,关键得看系统架构是怎么设计的,两者之间的耦合度有多高,如果说我们的业务逻辑里,用户每一次操作都必须实时同步调用搜狗的某个接口来获取数据,并且这个调用是直接嵌在数据库事务里,或者调用失败会触发长时间的阻塞和重试,那还真有可能间接地把数据库拖垮,这就好比一条马路,一个关键路口出了车祸堵死了,后面的车流很快就会倒灌,把整条路乃至相连的其他道路都堵得水泄不通。
(来源:开源中国技术讨论帖《如何避免第三方服务故障的连锁反应》)但如果我们当初设计系统时考虑得比较周全,做了充分的隔离和降级措施,那情况就会好很多,用了消息队列进行异步解耦,即使搜狗接口暂时不可用,请求也可以先堆积在队列里,不会直接冲击数据库;或者设置了合理的超时时间和熔断机制,调用失败快速返回,避免长时间占用数据库连接;再或者准备了降级方案,在第三方服务不可用时,使用默认值或缓存数据,保证核心流程还能走通,要是能做到这些,那搜狗服务就算真瘫痪几个小时,我们的MSSQL数据库大概率也能稳坐钓鱼台,不至于被牵连。
(来源:团队内部技术复盘会议纪要)可道理谁都懂,真要做到完美的隔离,成本和技术难度都不小,小公司资源有限,可能更倾向于快速实现业务功能,对这种潜在的“连锁故障”风险有时会心存侥幸,或者顾不上那么细,我们公司现在的情况就有点悬乎,有些地方感觉耦合还是挺紧的,每次第三方服务有点风吹草动,我都得紧盯着数据库的监控大盘,看连接数、CPU使用率、慢查询这些指标有没有异常波动,生怕哪个指标突然来个“旱地拔葱”。
(来源:个人工作笔记)我现在能做的,也就是多检查检查监控告警是否灵敏,和开发同学反复强调优化那些可能成为瓶颈的数据库查询语句,催着他们看看有没有可能在一些非核心业务上引入更彻底的异步化和降级策略,毕竟,数据库这东西,真是“养兵千日,用兵一时”,平时维护得好看不出来,一旦出问题就是大问题。“搜狗服务出问题了,MSSQL会不会也跟着瘫痪”这个担心,与其说是对某个具体事件的恐慌,不如说是对我们整个系统架构韧性和故障应对能力的一种持续拷问,真希望哪天我能彻底摆脱这种提心吊胆的感觉,那才说明我们的系统真的足够健壮了。
本文由太叔访天于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/72682.html