Redis卡顿到底是啥原因,性能瓶颈真没那么简单拆解不开

(引用来源:某技术社区资深运维工程师“老张”的分享实录,结合多位网友的实际案例)
Redis卡顿这个问题,就像是你家楼下那条平时畅通无阻的小路,突然在某天上下班高峰堵得水泄不动,你看着干着急,但堵车的原因可能千奇百怪:可能是前面出了个小车祸(某个慢查询),可能是红绿灯坏了(系统配置问题),也可能是突然涌进来一大批要去新开业超市抢购的车流(流量尖峰),甚至可能是路本身年久失修,坑坑洼洼(硬件或系统瓶颈),Redis的卡顿,就是这么个综合症,绝不是简单一句“内存不够”或者“CPU满了”就能打发的。
最容易被想到,但也最容易被误判的,就是所谓“资源不够”,很多人一发现Redis响应变慢,第一反应就是“是不是内存用光了?”或者“CPU是不是100%了?”(引用来源:常见新手运维思维),没错,如果物理内存真的被耗尽了,操作系统会开始使用Swap空间,把内存里不常用的数据挪到硬盘上,硬盘的速度跟内存比,那是自行车和高铁的差距,一旦发生Swap,Redis的性能就会断崖式下跌,但问题在于,很多时候你看到内存使用率可能才70%、80%,卡顿却已经发生了,这是因为Redis的内存管理机制,当Redis做持久化(比如生成RDB快照)或者主从同步时,它可能会fork出一个子进程来干活,这个fork操作在Linux下,如果内存数据量非常大,即使采用了写时复制(Copy-on-Write)技术,它本身也可能是一个很耗时的操作,会导致主进程短暂停顿,更关键的是,如果机器内存紧张,fork过程会非常挣扎,甚至失败,这带来的卡顿感就非常明显了,内存瓶颈不能只看使用率这个表面数字。
Redis的内部操作,如果使用不当,就是一颗颗定时炸弹,最典型的就是“慢查询”(引用来源:Redis官方文档重点警告项),Redis是单线程模型的,它像个只有一个收银员的超市,所有顾客(客户端请求)都得排队,如果前面有个顾客买了整整一购物车的东西,还要求每件商品都单独打包、开发票(这就是一个复杂的命令或者一次处理大量数据的命令),那后面排队的所有人都得干等着,哪些是“大顾客”呢?比如在没有设置合理分批大小的情况下,一次性获取一个包含几万成员的集合(SMEMBERS big_key),或者对一个超大的Hash键进行HGETALL操作,甚至是在生产环境误用了KEYS *这种会遍历所有键的命令,这些操作会长时间霸占着Redis唯一的处理线程,导致其他所有简单命令(如GET、SET)也无法执行,从监控上看就是这段时间的响应时间飙升,应用侧感觉就是Redis“卡死了”。
Redis不是活在真空里的,它所在的“生活环境”——也就是操作系统和硬件——对它影响巨大。(引用来源:某大型互联网公司基础设施团队的内部分析报告)Redis本身很健康,但架不住“邻居”太吵,最典型的就是CPU竞争,如果你把Redis和其他非常消耗CPU的应用(比如Java服务、大数据计算节点)部署在同一台物理机或虚拟机上,当这些邻居应用疯狂计算时,Redis能分到的CPU时间片就少了,自然响应会变慢,还有一种更隐蔽的情况是“内存大页”(Transparent Huge Pages)机制,这个机制的本意是优化大规模内存访问的性能,但对于Redis这种需要频繁fork子进程的数据库来说,启用内存大页可能会导致fork过程变得极其缓慢,从而引发严重的延迟问题,很多Linux发行版默认是开启这个功能的,这就需要运维人员特意去关闭它。
网络问题也常常被甩锅给Redis。(引用来源:众多开发者在社区中的求助帖)Redis性能再好,数据包也得在网络上传送,如果客户端和Redis服务器之间的网络链路出现波动、丢包或者带宽被打满,应用侧感受到的就是操作超时、响应慢,这时候你去查Redis的监控,可能发现Redis本身闲得发慌,但客户端已经哀嚎一片了,这就需要排查网络设备、防火墙规则、以及是否有其他应用占用了大量带宽。
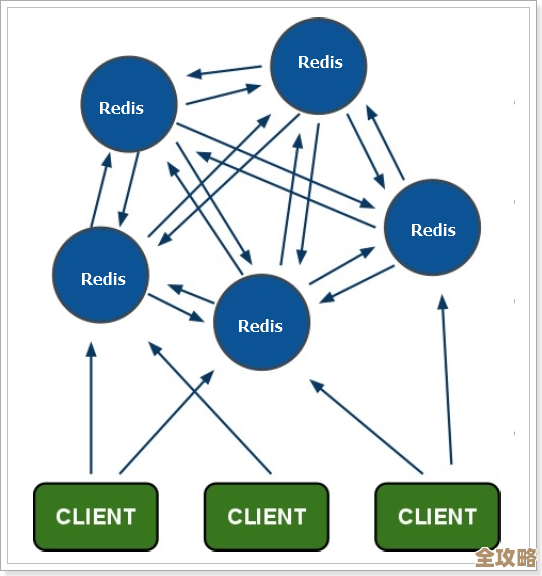
不得不提的是持久化和主从复制带来的影响。(引用来源:Redis持久化机制原理详解)为了数据安全,你肯定开启了AOF持久化或者定期生成RDB快照,AOF的配置策略很关键,如果设置为每次写入都同步刷盘(appendfsync always),那确实能最大程度保证数据不丢失,但每次写操作都要等待磁盘I/O完成,这会严重影响写入性能,如果磁盘本身又是那种慢速的机械硬盘或者云上的普通云盘,那卡顿就是家常便饭了,主从复制也一样,当从节点第一次全量同步,或者网络断开后重连需要进行部分重同步时,主节点需要生成并传输RDB文件,这个过程中主节点负载会增高,可能对正常服务造成影响。
你看,Redis卡顿这事儿,真不是那么简单,它可能是一个单一原因引发的,但更多时候是上述多种因素交织在一起形成的“完美风暴”,排查起来,就像破案一样,需要从监控指标(慢查询日志、内存、CPU、网络IO、磁盘IO)、系统配置、使用方式(是否有滥用的慢查询命令)、部署环境等多个维度去拉网式排查,才能找到那个真正的“罪魁祸首”。

本文由雪和泽于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/72618.html