想快速搞懂Oracle里那个哈希连接到底是咋回事,原理和用法简单聊聊

想快速搞懂Oracle里的哈希连接,咱们就别把它想得太复杂,你就把它当成一个非常高效的“配对游戏”,想象一下,你有两张长长的名单,一张是公司所有员工的名单(包含工号和姓名),另一张是公司所有电脑的分配记录(包含电脑编号和使用人工号),现在老板让你找出每个员工名下都分配了哪些电脑。
面对这个任务,你有几种笨办法,你可以用最老实的“嵌套循环”方法:拿起员工名单的第一行,然后抱着电脑分配记录表,从头到尾一行一行地比对工号,找到匹配的;然后再拿起员工名单的第二行,又一次把电脑分配记录表从头翻到尾……这样干,如果两张表都很大,你会累个半死,效率极低。
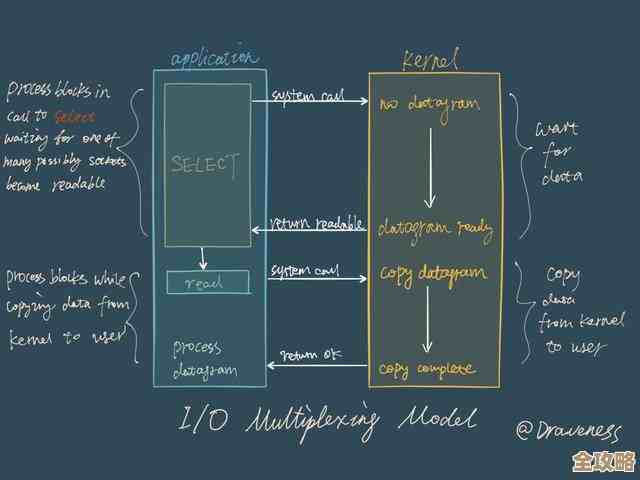
哈希连接则是一种聪明得多的办法,它不像嵌套循环那样一次次地遍历大表,而是分两步走,有点像“先整理,后配对”。
第一步:建造“小仓库”(构建阶段)
Oracle数据库的优化器会先看看这两张表,通常它会自动选择那个数据量比较小的表(比如我们例子里的员工表)作为“构建端”,它会在内存里为这张小表快速建立一个临时的“小仓库”,这个仓库就是“哈希表”。

这个哈希表是怎么建的呢?它会对连接键(在我们这个例子里就是“工号”)使用一个叫“哈希函数”的东西,这个函数你可以理解为一个神奇的“加工机”,你扔一个工号进去(A123’),它就会吐出一个固定的、长度较短的“仓库编号”(比如一个数字‘5’),这个加工过程非常快,而且同一个工号永远会得出同一个仓库编号。
这样,数据库就把小表(员工表)里的每一行数据,根据其工号计算出的仓库编号,分门别类地放到内存中对应的“货架”上,所有工号相关的员工信息都已经整整齐齐地排列在内存里这个哈希表里了,找起来会非常快。
第二步:上门“配对”(探测阶段)
建好了小仓库,接下来就要处理那个大数据量的表(电脑分配记录表)了,这个表被称为“探测端”。

数据库会开始一行一行地读取这个大表,每读一行,它就拿出这行记录里的工号,同样扔进那个“哈希函数”加工机,得到一个仓库编号,它就直接拿着这个编号,去第一步建好的那个内存小仓库里,找到对应的那个“货架”。
因为货架上的数据很少(理想情况下,哈希函数分布均匀的话,每个货架上可能只有一两行数据),它只需要在这个小小的货架上,精确地比对一下工号是否完全一致,如果一致,恭喜,配对成功!数据库就把员工表这行的信息(姓名)和电脑分配记录表这行的信息(电脑编号)组合起来,作为结果集的一行输出。
然后它继续处理大表的下一行,重复这个过程:计算哈希值 -> 去对应货架 -> 精确匹配 -> 输出结果。
这么干有啥好处?

最大的好处就是快!因为它避免了对大表进行多次全表扫描,嵌套循环是拿着小表的一行去扫一遍整个大表,而哈希连接是只扫一遍小表(建仓库)和一遍大表(上门配对),当两个表都很大的时候,这种效率优势是压倒性的。
那什么时候会用上它呢?
根据Oracle官方文档(如《Oracle Database Concepts》)中的描述,哈希连接通常在以下情况被优化器优先选择:
- 连接的表足够大: 如果表很小,嵌套循环可能更快,因为建立哈希表本身也有开销,但当数据量增大到一定程度,哈希连接的优势就体现出来了。
- 连接条件不是等值连接: 哈希连接最适合处理像这样的等值连接,如果是范围查询(比如
大于号小于号),它就不太适用了。 - 有足够的内存: 构建哈希表需要在内存中进行,如果内存不够,数据库就不得不把一部分哈希表临时写到硬盘上,这会大大降低速度,拥有充足的PGA(程序全局区)内存对哈希连接的性能至关重要。
简单总结一下:
你就记住,哈希连接像个高效的配对员,它不傻乎乎地来回翻大本子,而是先花点时间把小名单整理成一个有编号的卡片箱(构建哈希表),然后拿着大名单,每看到一个名字,就根据编号直接去卡片箱里那个小格子里找,瞬间完成配对,当你要处理的数据量很大时,这个方法比那种蛮干的方法不知道高到哪里去了。
在实际的Oracle数据库里,优化器会根据表的统计信息(比如大小、索引情况)自动决定是否使用哈希连接以及如何使用,你通常不需要手动指定,但理解它的原理,能帮助你在遇到SQL性能问题时,知道可能的原因出在哪里,比如是不是因为内存不足导致哈希连接效率下降了。
本文由太叔访天于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/72208.html