百万级MSSQL数据库表咋管理,实践中遇到的那些事儿和经验分享

这事儿说起来,都是实战里一点点摸爬滚打出来的,当年第一次接手一个几百万行数据的表,感觉还挺牛,结果没过多久,查询就慢得像蜗牛,页面转圈圈能转半天,用户投诉电话都快打爆了,从那以后,就开始了跟大数据表斗智斗勇的日子。
第一关,也是最重要的,就是给表找个好“目录”——索引。
刚开始啥也不懂,就觉得主键有个索引就够了,后来发现大错特错,这就像一本超厚的电话簿,如果没有按姓氏拼音排序,你想找个人得从头翻到尾,累死也找不到,索引就是那个拼音排序,但索引也不是乱建的,建多了, insert、update、delete的时候就得更新所有相关的索引,写操作就慢了,相当于你每在电话簿里加个人,都得重新排序一遍,也挺费劲。
经验是,得盯着那些经常用在where条件、order by排序和join连接上的字段来建索引,比如用户表,按注册时间、最后登录时间、状态这些字段建组合索引,效果立竿见影,有个教训挺深刻,有次我们有个查询突然变慢,查了半天,发现是因为数据量上去后,一个原本选择性很好的索引变得没那么好了,就是重复值太多了,索引效率下降,后来只好调整了索引字段的顺序,才解决问题,这事儿让我明白,索引不是一劳永逸的,得定期复查,看看有没有“失效”的或者需要优化的。
第二关,得学会给表“分家”——分区。
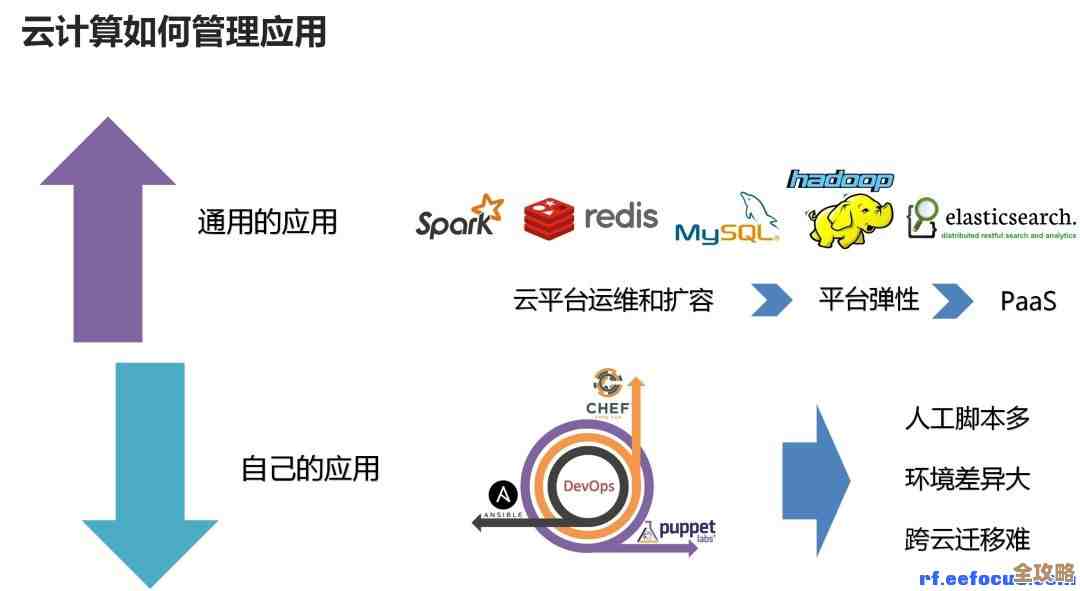
当表真的大到千万级甚至更多,光靠索引就有点力不从心了,这时候就得考虑分区,简单说,就是把一张大表按某个规则(比如时间,按月或按年)切成很多个小物理文件,但逻辑上还是一张表,好处太大了!比如我们要查询最近一个月的数据,数据库可以只扫描存放最近一个月数据的那个分区,不用去翻一整年的历史数据,速度飞快,还有备份和归档,我们可以只备份最新的分区,或者把最早的那个分区整个切出来,移到便宜的存储上做历史数据归档,大大节省空间和备份时间。

实践中分区键的选择是关键,我们有个日志表,开始傻乎乎地按自增ID分区,结果屁用没有,因为查询永远是按时间查,后来改成按日志创建时间分区,查询性能提升了几十倍,还有一次,做数据归档删除旧数据,如果是普通表,一个delete语句能锁表锁到天荒地老,业务直接停摆,用了分区后,直接switch出去那个旧分区,然后truncate,几乎是瞬间完成,对业务零影响,这个体验真的太爽了。
第三关,是跟SQL语句本身“较劲”。
很多时候慢,不是数据库的锅,是写的SQL太烂了,比如动不动就select *,把不需要的字段全捞出来,网络传输和内存占用都浪费,还有那种复杂的嵌套查询,有时候拆成几个简单的语句,用程序逻辑处理,反而更快,多表连接的时候,连接条件没写好,可能造成笛卡尔积,数据量爆炸式增长。
我们养成的一个好习惯是,上线前一定要用SQL Server自带的“执行计划”功能看看,这个功能能图形化地告诉你,数据库是怎么执行你这句SQL的,是在全表扫描(最差的情况)?还是用了索引查找(好的情况)?哪里开销最大,一目了然,很多性能问题,一看执行计划就找到病根了。

第四关,日常的“保养”不能少。
数据库跟车一样,需要定期保养,比如索引碎片多了,查询效率就会降低,得定期重建或者重新组织索引,还有统计信息,这玩意是数据库用来决定怎么执行查询的“天气预报”,如果信息过时了,数据库可能就会选一条傻乎乎的执行路径,所以我们设置了自动更新统计信息的任务。
说说心态。
管理百万级的数据库,不能等到出问题了再救火,得有监控,时刻关注磁盘空间、CPU、内存压力、慢查询日志,很多时候,一个潜在的慢查询,在数据量小的时候没事,一旦数据量上来了就是灾难,所以要有前瞻性,提前优化。
这块儿没什么银弹,就是一个不断优化、不断调整的过程,从索引、分区、SQL写法到日常维护,每个环节都做好了,大数据表也能变得服服帖帖,这些经验,都是实打实从坑里爬出来后总结的,希望对你有用。
本文由召安青于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/72168.html