Redis架构深度剖析,聊聊那些基于红色性能优化的细节和实战经验

(引用来源:Redis官方文档、阿里云开发者社区技术博客、高可用架构技术文章、个人实战经验)
Redis的性能优化是一个从宏观架构到微观细节都需要仔细考量的过程,很多人以为用了Redis就万事大吉,但如果不注意细节,它反而会成为系统的瓶颈,下面就直接聊聊那些在实际项目中真正起作用的优化点。
从架构层面看,避免Redis单点部署是底线,单节点Redis一旦宕机,整个缓存层就崩溃了,主从复制(Replication)是最基本的保障,但主从切换需要人工或哨兵(Sentinel)介入,存在延迟和风险,对于要求高可用的生产环境,Redis Cluster集群模式是更稳妥的选择,它通过分片(Sharding)将数据分布到多个节点上,不仅提高了容量上限,也实现了真正的分布式和高可用,但这里有个关键细节:Redis Cluster的槽位(slot)分配是固定的,在进行节点扩缩容时,会触发槽位和数据迁移,这个过程如果数据量巨大,会对性能产生显著影响,建议在业务低峰期操作,并做好监控。
(引用来源:个人实战经验)我们曾经在迁移一个大型集群时,因为没预估好数据迁移带来的网络带宽占用,差点拖垮了同机房的其它服务,架构设计时就要考虑好未来的扩展性,避免临时抱佛脚。
说到性能,网络开销往往是第一个瓶颈,Redis本身是基于内存的,速度极快,但每次命令执行都伴随着网络往返(Round-Trip Time, RTT),一个常见的误区是,在代码里写一个循环,频繁地调用Redis,比如要获取100个用户信息,如果用100次GET命令,就会产生100次网络开销,正确的做法是使用批处理命令,比如用MGET一次获取,或者用Pipeline将多个命令打包一次发送。Pipeline并不是原子操作,但它能极大地减少RTT,提升吞吐量,需要注意的是,打包的命令数量也不是越多越好,要避免单个Pipeline过大导致Redis长时间阻塞,影响其他请求。
(引用来源:Redis官方文档关于Latency的说明)另一个网络相关的优化是连接池(Connection Pool),避免为每个请求都创建和销毁连接,使用连接池复用连接,可以显著减少TCP三次握手和连接断开的开销。
内存优化是另一个重头戏,Redis是内存数据库,内存就是最宝贵的资源,首先要选择合适的数据结构,存储一个用户的好友列表,用Set可能很直观,但如果好友ID是连续的整数,使用IntSet编码的Set会比使用哈希表节省大量内存,再比如,存储一个对象的多个字段,很多人习惯用多个String类型的Key,这会导致大量Key的元数据浪费内存,应该使用Hash结构,它能够高效地存储多个字段,尤其是在Redis 3.2之后,Hash的ziplist编码优化了对小哈希的存储效率。
(引用来源:阿里云开发者社区关于Redis内存优化的案例)有一个经典案例是,某应用将数千万个对象的字段拆成独立的Key存储,内存占用高达几十GB,后来改为使用Hash结构存储,内存使用量直接下降了70%以上,这就是数据结构的威力。
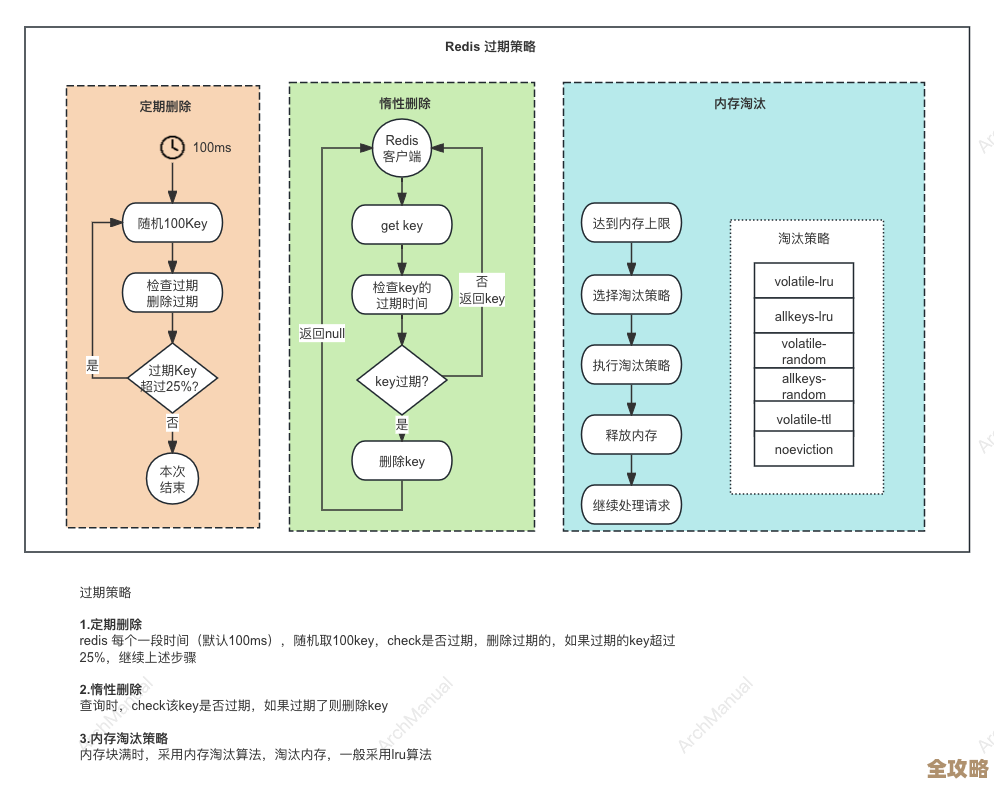
键名(Key)的设计也暗藏玄机,有些开发者喜欢用很长的、语义清晰的Key,比如user:profile:1234567890,这没问题,清晰易懂,但如果每个Key都这么长,亿万级别的Key会额外占用巨大的内存,可以考虑使用简写,比如u:p:1234567890,在内存和可读性之间取得平衡,一定要给Key设置过期时间(TTL),除非它是永久数据,这不仅能避免内存泄漏,也是数据安全性的要求。
持久化策略的选择直接影响性能和数据安全,RDB持久化生成数据快照,文件小,恢复快,但可能会丢失最后一次快照之后的数据,AOF持久化记录 every write operation,数据安全性高,但文件大,恢复慢,在生产环境中,通常建议同时开启RDB和AOF(Redis 4.0后推荐使用RDB-AOF混合持久化模式),这里的一个优化点是调整AOF的刷盘策略appendfsync,默认的everysec在性能和安全性之间取得了很好的平衡,它每秒刷盘一次,最多丢失1秒数据,如果对性能要求极高且能容忍少量数据丢失,可以设置为no,让操作系统决定何时刷盘;如果对数据安全要求极高,则设置为always,但这会显著影响性能。
(引用来源:高可用架构文章关于Redis持久化的分析)需要警惕的是,当AOF文件过大时,Redis会进行重写(Rewrite),这个过程会fork子进程,如果此时内存占用很大,fork操作可能会很慢,甚至导致Redis短暂停顿,监控内存和AOF文件大小至关重要。
监控和慢查询日志是优化的眼睛,一定要开启Redis的慢查询日志(slowlog),设置一个合理的阈值(比如10毫秒),定期检查哪些命令执行得慢,可能是大Key导致的,也可能是复杂度过高的命令(比如对一个百万成员的Set执行SMEMBERS),发现慢查询后,就要针对性优化,比如将大Key拆分,或用SSCAN代替SMEMBERS进行迭代查询。
Redis的性能优化不是一蹴而就的,它贯穿于架构设计、开发编码和运维监控的全生命周期,每一个微小的优化,积累起来就能带来质的飞跃,核心思想就是:减少网络往返、高效利用内存、选择合适的数据结构和持久化策略,并辅以持续的监控和分析。

本文由凤伟才于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/72046.html