Sybase SQL Server日志那些常见坑和问题你知道多少没搞清楚的地方不少

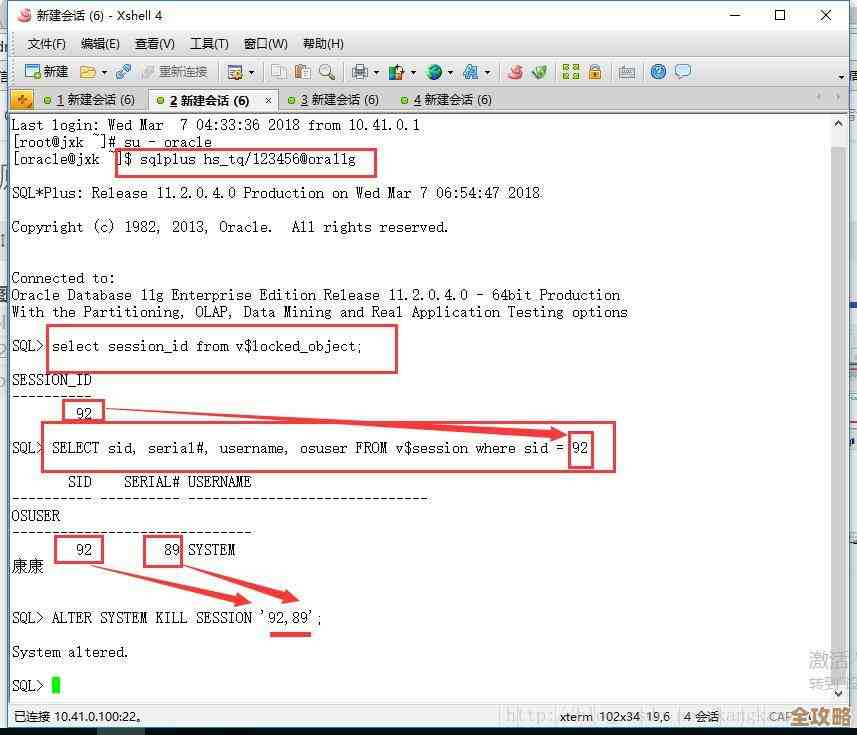
一个最经典也最让人头疼的坑就是日志空间被填满,这个问题几乎每个Sybase管理员都遇到过,来源自用户普遍反映的情况是,数据库突然就“挂起”了,所有需要写日志的操作都停了,前端应用报错,这时候去查,会发现日志段(log segment)的使用率是100%,原因多种多样:可能是一个超大的事务没提交,比如不小心没写where条件的update或者delete,一下子处理了几百万行数据,所有这些操作细节都要记日志;也可能是日志备份没做或者失败了,导致旧的日志记录不能被截断和重用;又或者是业务高峰时期,正常的事务量就把预留的日志空间用完了,处理起来很棘手,如果是因为大事务,可能得忍痛杀掉这个进程,但这又会引起回滚,进一步消耗资源和时间,预防是关键,要监控大事务、设置合理的日志大小、并确保日志备份任务正常运行。
第二个常见问题与日志和备份的误解有关,很多人,尤其是从其他数据库转过来的管理员,会误以为Sybase的数据库完整备份(dump database)会自动截断日志,这是完全错误的,来源自Sybase官方文档和多个入门指南都强调过,完整备份只备份数据页和部分日志,它不会释放日志空间,真正负责截断日志、腾出空间给新事务用的是事务日志备份(dump transaction),如果只做完整备份,从不做日志备份,那么日志只会一直增长直到占满所有空间,另一个相关的混淆点是“with truncate_only”和“with no_log”这两个选项,在老版本中,人们会在日志满时用“dump tran ... with no_log”来紧急截断日志,但这是一种非常危险的操作,因为它不记录日志,会破坏日志链,可能导致数据库不一致,而且如果之后发生故障,从这个点往后的数据都无法恢复,官方早已不建议使用,但在网上搜解决方案时,还是能看到很多老文章提到它,误导新人。
第三个坑点在于日志的读取和分析非常困难,不像一些现代数据库有直观的工具可以查看日志内容,Sybase ASE没有提供官方的、易于使用的图形化日志浏览工具,来源自技术社区如CSDN、ITPUB上的讨论,DBA们通常需要依赖第三方工具(如Lumigent Log Explorer或ApexSQL Log)来解析日志文件,而这些工具往往价格不菲,自带的dbcc log命令虽然能看,但输出的是原始、晦涩难懂的数据页信息,对于诊断“某个特定的数据是谁在什么时候修改的”这种问题,几乎没什么直接帮助,这使得排查数据误操作、进行审计或者做精细的恢复变得异常困难,成为了一个技术门槛和成本上的“坑”。
第四个问题是关于复制环境(Replication)下的日志问题,Sybase的复制技术(如Replication Server)严重依赖事务日志来捕获数据变更,来源自Sybase复制相关的故障排查手册,这里容易出几个岔子,一是日志读取进程(Log Transfer Manager, LTM)如果出现延迟或中断,会导致分发数据库的事务日志堆积,因为被标记为要复制的日志记录在成功分发出去之前是不能被截断的,二是如果复制链路的配置有问题,比如订阅服务器宕机时间长,主站点的日志可能会因为要保留很长的历史记录而被撑爆,管理复制环境下的日志,需要更精细的监控和更深入的复制知识,对管理员的要求更高。
第五个常被忽略的细节是模型数据库的日志配置,来源自一些“血泪教训”式的经验分享,很多管理员给用户数据库设置了合理的日志大小时,却忘了模型数据库(model database)的日志默认很小,当有新人执行create database命令时,如果没指定日志大小,新库会继承模型数据库的配置,结果就是一个重要的业务数据库一建起来,日志可能只有区区几MB,上线没多久就因为日志空间不足而崩溃,这是一个典型的“灯下黑”问题。
还有一个性能方面的潜在问题:日志I/O瓶颈,来源自性能调优指南,事务日志是串行写的,所有修改都必须顺序记录到日志文件中,如果日志文件所在的磁盘速度慢、或与其他高I/O操作(比如数据文件、tempdb)共享一个物理磁盘,很容易形成瓶颈,这会拖慢整个数据库的写操作速度,因为每个事务都要等待日志写操作完成,最佳实践总是建议将日志文件放在独立的、高速的磁盘上,以确保日志写入的流畅性。
Sybase SQL Server的日志管理是一块硬骨头,它不像一些更自动化的数据库系统,需要管理员具备扎实的理解和主动的管理策略,从空间规划、备份策略、异常监控到性能隔离,任何一个环节疏忽都可能带来严重的问题。

本文由度秀梅于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/71617.html