用Redis缓存到底该放啥,才能真提升应用速度和响应体验

关于用Redis缓存到底该放啥才能真提升应用速度和响应体验,关键在于理解一个核心原则:缓存那些“计算起来贵”但“变化不太快”的数据,说白了,就是把你应用中那些需要花费较长时间去数据库查、或者需要复杂计算才能得到结果,但又不是每分每秒都在变的信息,提前算好放在Redis里,下次需要的时候,直接从Redis这个高速内存仓库里拿,省去了慢吞吞的数据库查询或复杂计算过程,速度自然就上去了。
以下几类数据是往Redis里放的“常客”,效果立竿见影:
第一,热点数据和排行榜。 这是Redis最经典的用法,比如新闻网站的头条文章、电商网站首页推荐的商品、社交App的热门帖子,这些内容访问量巨大,如果每次请求都去查数据库,数据库压力会非常大,容易成为瓶颈,把它们缓存起来,绝大部分用户看到的都是缓存内容,应用响应会非常快,排行榜更是如此,利用Redis的有序集合(Sorted Set)数据结构,更新和查询排名效率极高,非常适合做实时榜、热度榜。(来源:Redis官方文档中关于使用案例的介绍)
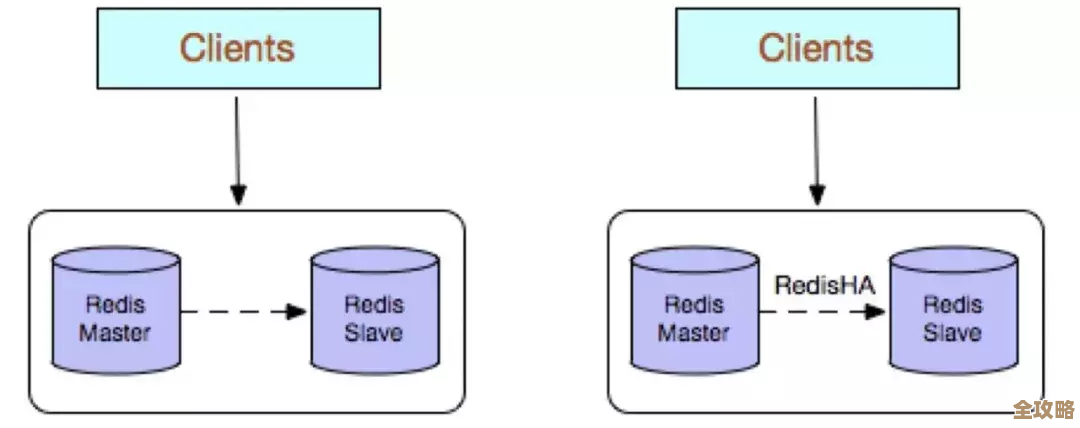
第二,会话数据(Session)。 用户登录后,服务器需要记住他是谁,如果把Session信息存在服务器自己的内存里,一旦服务器重启或者用户下次请求被分配到另一台服务器,登录状态就丢了,把Session统一存到Redis中,所有服务器都能读取和修改,这样就实现了“无状态”的服务架构,应用可以轻松扩展,用户的登录体验也更连贯。(来源:广泛采用的分布式Session解决方案)
第三,需要频繁读取的全局配置或元数据。 比如电商网站的商品分类、城市列表,内容管理系统的网站设置、广告位信息,这些数据通常由后台管理员修改,变动不频繁,但前端几乎所有页面都可能用到,每次都查数据库没必要,放在Redis里,所有服务实例共享一份,访问速度极快,还能显著降低数据库的压力。(来源:常见的企业级应用架构实践)
第四,应对“惊群效应”的查询结果。 有时候会遇到一种情况:某个热点数据缓存突然失效了,比如一个热门商品秒杀刚开始,缓存过期,这时瞬间涌来成千上万的请求,发现缓存没了,全都同时去查询数据库,可能导致数据库瞬间被打垮,对于这种场景,可以用Redis的分布式锁机制,只让一个请求去数据库查询并重建缓存,其他请求等待并直接使用新缓存,从而保护后端数据库。(来源:高并发场景下的缓存经典问题与解决方案)
第五,简单的计数器和限流控制。 比如文章的阅读量、用户的点赞数,这种操作非常频繁,如果每次+1都直接写数据库,数据库的IO压力会很大,用Redis的原子操作(比如INCR)来实现计数器,速度极快,然后再定期将结果同步到数据库,同样,限制一个IP地址一分钟内只能请求60次API,用Redis来记录和判断,也非常高效。(来源:Redis在计数器与速率限制方面的应用范例)
什么东西最好不要往Redis里放呢?
- 变化极其频繁的数据: 如果一个数据每秒都在变,那么你缓存的更新速度可能都跟不上它变化的速度,缓存很快就会失效,失去了意义,反而增加了系统的复杂性。
- 巨大的二进制文件(如图片、视频): Redis是内存数据库,内存资源非常宝贵,存放大文件会快速耗尽内存,成本极高,而且Redis处理大Value的性能也会下降,这类数据应该用对象存储(如S3、OSS)或CDN。
- 需要复杂关系查询的数据: Redis是键值存储,不适合做像SQL那样的多表关联、复杂条件查询,数据的结构和关系还是应该交给关系型数据库来处理。
- 永远不能丢的关键数据: Redis虽然可以配置持久化,但它的首要目标是保证速度,最核心的业务数据(如交易订单、账户余额)的“唯一真相源”必须是像MySQL这类具备强一致性保证的数据库,Redis只能作为加速用的副本。
用好Redis提升体验的诀窍在于:
- 目标明确: 缓存是为了加速读多写少、计算成本高的数据访问。
- 策略得当: 给缓存设置合理的过期时间(TTL),避免数据永远不更新变成“脏数据”。
- 分清主次: 清楚知道哪些数据适合缓存,哪些不适合,Redis是出色的辅助,而不是要取代主数据库。
只要遵循这些原则,把合适的“货物”放进Redis这个高速仓库,你的应用速度和响应体验就能获得实实在在的巨大提升。

本文由邝冷亦于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/71570.html