一篇文章带你快速了解用 OpenTelemetry 在 Kubernetes 里怎么做全链路观测,虽然细节还得自己琢磨

(引用来源:主要基于OpenTelemetry官方文档、CNCF社区博客以及如Jaeger、Prometheus等可观测性工具的实践指南中的常见模式,进行综合阐述)
你想知道怎么在Kubernetes这个管理很多小应用(容器)的大管家那里,看清楚它们之间是怎么互相打招呼、传东西的吗?尤其是当一个请求像击鼓传花一样,从一个服务传到另一个服务,怎么知道它在哪儿卡住了、为什么慢?OpenTelemetry(简称OTel)就是现在最流行的“侦探工具包”,专门干这个事,这篇文章就带你快速走一遍流程,但就像标题说的,具体怎么接线、怎么配置,还得你自己亲手试试。
第一步:先搞明白要收集什么“线索”
全链路观测,说白了就是把一个请求的完整旅程记录下来,这需要三种主要的线索:
- 链路(Traces):这是最重要的部分,它就像给一个请求分配了一个唯一的身份证号(Trace ID),这个请求每到一个服务,都会留下一个记录(Span),说明“我在这里干了啥,花了多长时间”,所有这些记录串起来,就形成了这个请求的完整路径图,用户点击下单,这个请求先到了网关(Span A),网关又去叫醒了用户服务(Span B),用户服务又去查询了数据库(Span C),这样,如果下单慢了,你一眼就能看出是哪个环节拖了后腿。
- 指标(Metrics):这是关于服务的“体检报告”,你的服务每秒处理多少个请求?当前的CPU和内存用了多少?平均响应时间是多少?这些数字能让你从整体上了解服务的健康状况,发现趋势性的问题,比如流量是不是突然变大了。
- 日志(Logs):这就是服务自己写的“日记”,记录了一些具体的事件和错误信息,无法连接数据库”、“用户XXX登录成功”,日志最详细,但如果没有和链路关联起来,就像一堆散落的日记页,很难快速找到某个具体问题对应的记录。
OpenTelemetry的强大之处在于,它提供了一套统一的标准来生成、收集这些线索,尤其是能把它们关联起来,你可以在日志里也记录下当前请求的Trace ID,这样查日志的时候就能直接定位到出问题的那个具体请求链路了。
第二步:在Kubernetes里部署“侦探总部”
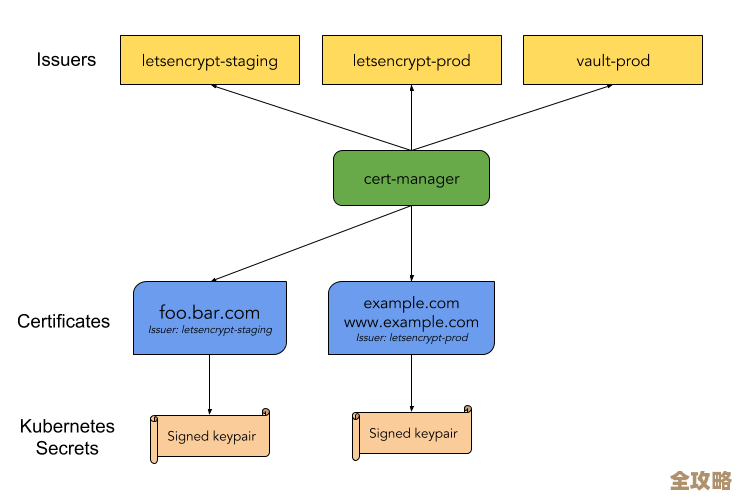
光有线索还不够,得有个地方来接收、存储和分析这些线索,在Kubernetes里,你通常需要部署一个“可观测性后端”,这不是一个单一的东西,而是一组组件:
- 收集器(Collector):这是核心枢纽,你的所有应用产生的链路、指标数据,都先发送给这个Collector,由它来负责接收、处理(比如过滤掉一些敏感信息)、然后转发到后端的存储系统,在Kubernetes里,你通常会把它部署成一个DaemonSet(每个节点上都跑一个)或者Deployment(集中部署几个)。
- 存储与展示系统:Collector本身不存数据,它需要把数据送到别的地方,对于链路数据,常用的有Jaeger、Tempo;对于指标数据,Prometheus是绝对的主流;日志可以用Loki等,现在也有很多商业或开源的全能型平台,能同时处理这三种数据。
你的Kubernetes集群里,除了跑业务应用的Pod,还会多出一些跑OTel Collector、Jaeger、Prometheus的Pod。
第三步:让你的应用变成“线人”
要让你的应用程序学会用OpenTelemetry的SDK(软件开发工具包)来生成并吐出线索,这个过程叫“插桩”,有两种主要方式:
- 自动插桩:这是最省事的,对于很多主流编程语言(Java, Python, Node.js等),OTel提供了“自动插桩”的库,你基本上不需要修改代码,只需要在启动你的应用时,把这个库像插件一样引入(比如Java的-javaagent参数),它就能自动帮你拦截常见的框架操作(比如HTTP请求、数据库调用),并生成对应的Span,这能快速获得大部分所需的链路信息。
- 手动插桩:当自动插桩不能满足需求时,比如你想记录一些业务逻辑内部的关键步骤,你就需要在代码里手动写:“从这里开始计时”(开始一个Span),到“这里结束”(结束这个Span)。
无论用哪种方式,你都需要配置你的应用,告诉它:“请把生成的线索数据,发送到那个叫OTel Collector的服务地址上去”,这个地址通常是在Kubernetes内部的一个Service。
第四步:把一切串联起来
“线人”(应用)在生成线索,“总部”(Collector和后端)也准备好了,但还差一点:怎么让一个请求的Trace ID在服务之间传递?这就是“上下文传播”要做的事。
服务A调用服务B时,OTel的SDK会自动在HTTP请求头里加上Trace ID等信息,服务B收到请求后,它的SDK会从请求头里读出这个ID,然后它创建的新Span就会自动归属于这个已有的Trace,这样,链路就串起来了,这个过程通常也是由SDK自动完成的,你只需要确保使用兼容的传播协议(比如W3C的Trace Context标准)即可。
看板和大盘
当数据都流畅地进入后端存储后,你就可以用各种可视化工具来查看了,用Jaeger的界面可以搜索和查看一条条具体的请求链路;用Grafana连接Prometheus数据源可以制作监控大盘,实时展示CPU使用率、错误率等关键指标;还可以把链路、指标、日志在Grafana上关联起来展示,实现真正的全链路观测。
总结一下在Kubernetes里的关键步骤:
- 规划与部署后端:先想好用啥存数据(Jaeger? Prometheus?),然后在K8s里把它们和OTel Collector一起部署好。
- 改造应用:给应用加入OTel SDK(自动或手动插桩),并配置它指向Collector Service。
- 验证与排查:发起一个测试请求,去Jaeger等界面看看链路是否完整生成,确认服务间调用关系是否正确。
这个过程听起来步骤清晰,但真做起来,你会遇到很多需要“自己琢磨”的细节:比如Collector的配置文件怎么写才能正确接收和转发数据?如何给链路数据打上K8s的标签(如Pod名称、Namespace)以便过滤?如何设置采样率以免数据量太大?如何保证整个链路的性能损耗在可接受范围?这些就是深入实践时需要一一攻克的具体问题了,希望这个快速的概览能给你一张清晰的“寻宝图”,让你知道该从哪个方向开始你的探索。

本文由符海莹于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/71414.html