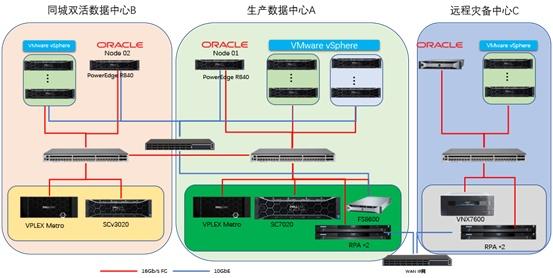
DB2分区里数据怎么不均匀,导致性能差,想办法重新调整分布的那些事

想象一下,你管理着一个巨大的仓库,这个仓库被分成了好几个大小相同的区域,这就是DB2里的表分区,你的本意是好的,把不同的货物按照生产日期(比如按月份)放进不同的区域,这样,当有人来查询2023年11月的货物时,你只需要去“2023年11月”那个区域找就行了,不用翻遍整个仓库,速度自然快很多,这就是分区带来的好处。
问题来了,由于业务的特点,某些月份的货物特别多,双十一”所在的11月,货物堆积如山,把那个分区塞得满满当当,几乎要爆仓;而像2月这种淡季,分区里却空空荡荡,这就是所谓的“数据倾斜”或“数据分布不均匀”,这时候,那个最忙、数据最多的分区就成了整个系统的“短板”。(来源:基于DB2数据库管理中的常见性能问题场景)
当数据库需要执行一个涉及全表的查询时(比如年底盘点),数据库引擎会同时调动所有分区一起工作,理想情况下,每个分区工作量差不多,同时干完,效率最高,但现在,其他分区很快就扫描完了自己那点数据,然后只能干等着那个数据量巨大的“11月”分区慢吞吞地干活,整个查询的完成时间,不取决于最快的分区,而取决于最慢的那个,这就导致了整体性能急剧下降,这就像一场团体赛跑,队伍的成绩取决于跑得最慢的那个人。(来源:对DB2并行查询原理的通俗化解释)
不仅如此,那个热点分区所在的物理磁盘I/O压力会非常大,读写操作都集中在那里,很容易形成瓶颈,数据库维护操作,比如备份、重组、跑统计信息,也会因为这一个分区的“臃肿”而变得异常缓慢。
发现问题后,我们该怎么办呢?不能眼睁睁看着系统越来越慢,核心思路就是“重新分货”,让每个区域的工作量重新变得均衡,有几种常见的办法:
第一种办法,也是最根本的,重新划分分区策略”,当初我们按月份分,发现不均匀,那能不能换一种分法?不按自然的月份了,而是按数据量的预估来划分,假设我知道每年“双十一”期间的数据量大概是平时的三倍,那我可以在设计分区时,把11月的数据拆分成三个分区:11月1-10日一个分区,11月11-20日一个分区,11月21-30日一个分区,而对于数据量少的2月,可能整个月作为一个分区就够了,通过调整分区键(partition key)和分区范围(partitioning range),从源头上让数据分布更合理,但这通常需要重建表,是个大手术,需要在业务低峰期谨慎进行。(来源:DB2官方文档关于表分区设计的最佳实践)
第二种办法,适用于已经存在的数据倾斜,叫做“数据重新分布”,DB2提供了像REDISTRIBUTE DATABASE PARTITION GROUP这样的工具命令,这个命令的作用,就是在不改变现有分区逻辑定义的情况下,强制性地将数据在各个物理分区之间进行“搬运”,直到每个分区上的数据量达到平衡,这个过程就像是仓库管理员发现11月分区太满后,主动把里面的一部分货物搬移到2月那个空闲的分区里去,虽然它们还是属于11月的货,但物理上存放在别处,以减轻单个分区的压力,这个操作同样对系统资源消耗很大,但比重建表的影响要小一些。(来源:DB2管理指南中关于重新分布分区组数据的说明)
第三种办法,是“引入更灵活的分布键”,这通常发生在DPF(数据库分区特性)环境中,也就是数据不仅按范围分,还可能分布在多台服务器上,这时候,除了时间,我们还可以结合其他字段,比如客户ID、订单ID等,作为额外的分布键(distribution key),这样,即使某个时间点的数据量大,但这些数据也会因为客户ID的不同而被散列(Hash)到不同的物理节点上,从而避免单个节点成为热点,这相当于在按日期分区域的基础上,在每个区域内又按照客户姓氏的首字母进行了二次分柜,进一步分散了压力。
除了这些主动调整的方法,日常的监控也至关重要,需要定期查看系统目录视图,比如SYSCAT.DATAPARTITIONS,监控每个分区的大小和记录数,一旦发现某个分区显著大于其他分区,就要引起警觉,提前规划调整方案。
DB2的分区是个强大的功能,但用不好也会带来麻烦,数据分布不均匀是导致分区表性能差的常见原因,解决之道在于识别出热点分区,然后通过调整分区策略、执行数据重分布或优化分布键等方式,努力让数据在各个分区上“雨露均沾”,这样才能让并行的优势真正发挥出来,避免让整个数据库系统被一个“胖”分区拖了后腿,这个过程需要持续的关注和调整,没有一劳永逸的解决方案。

本文由称怜于2025-12-29发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/70801.html