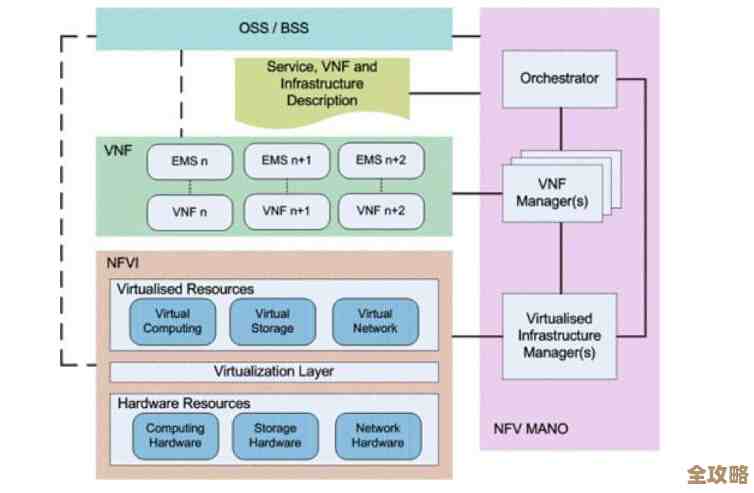
怎么看Redis性能状态啊,哪些指标能帮你快速了解redis运行情况

要了解Redis的性能状态,就像给汽车做体检一样,不能光看它能不能开动,还得检查发动机、油耗、刹车是否灵敏,Redis也有一系列关键的“体检指标”,能帮你快速判断它是不是在“健康”运行,这些信息主要可以通过Redis自带的INFO命令获取,或者在各种监控工具(如Grafana、Prometheus)中看到这些数据的可视化展示。
第一,先看整体状态和内存使用情况,这是基础。
运行INFO命令,开头部分会有一个# Stats的段落,这里面是核心的运行统计,首先关注连接数和命令处理数。

- 连接数(connected_clients):这个数字表示当前有多少个客户端连到了Redis上,如果这个数字异常的高,比如平时就几十个,突然变成几千个,那可能是有程序异常,没有正确关闭连接,导致了“连接泄漏”,这会慢慢拖垮Redis。
- 每秒处理命令数(instantaneous_ops_per_sec):这个指标直接反映了Redis的忙碌程度,它告诉你Redis在一秒钟内处理了多少个命令,如果这个值持续非常高,接近了你服务器CPU的处理上限,说明Redis可能已经不堪重负,需要考虑优化业务逻辑或者扩容了。
内存是Redis的命根子,所以内存指标至关重要,看# Memory段落。
- 已使用内存(used_memory):这是Redis当前使用了多少内存,你需要结合你给Redis设置的最大内存(
maxmemory)来看,如果used_memory快接近maxmemory了,Redis就会根据你设置的策略(比如删除最近最少使用的键)来淘汰数据,这可能会影响业务。 - 内存碎片率(mem_fragmentation_ratio):这个值等于
used_memory_rss(操作系统分配给Redis的物理内存)除以used_memory(Redis实际存储数据使用的内存),这个比值理想情况下在1.0左右,如果大于1.5,说明内存碎片比较严重,分配的内存没有被有效利用;如果小于1.0,那更糟糕,说明操作系统正在使用交换分区(swap),Redis的性能会急剧下降,因为磁盘比内存慢太多了。
第二,关注错误和延迟,这些是直接的问题信号。

还是在# Stats段落里,有几个关键的“错误计数器”。
- 被拒绝的连接数(rejected_connections):当Redis达到最大客户端连接数上限(
maxclients)时,新来的连接就会被拒绝,这个数字如果大于0,说明你的连接数设置可能不够用,或者又出现了连接泄漏的问题。 - 键空间命中率(keyspace_hits和keyspace_misses):用
keyspace_hits除以(keyspace_hits+keyspace_misses)就能算出命中率,这个指标对使用Redis做缓存的应用特别重要,命中率越高,说明缓存的效果越好,大部分请求都直接从Redis获取了数据,减轻了后端数据库的压力,如果命中率很低(比如低于90%),你就需要检查一下缓存策略了,是不是缓存的数据很快就被淘汰了,或者缓存键的设计不合理。
除了这些数字,延迟(Latency) 是衡量用户体验最直接的指标,Redis提供了LATENCY命令来监测延迟事件,你可以理解为你发一个命令给Redis,到收到回复花了多长时间,如果平时都是零点几毫秒,突然某个时刻变成了几十甚至几百毫秒,那肯定是出了什么问题,比如正在做持久化、发生了内存交换、或者有特别耗时的命令在执行。

第三,不能忽视持久化和主从复制的状态。
如果你的Redis配置了数据持久化(RDB快照或AOF日志)或主从复制,这些方面的监控同样重要。
- 持久化延迟:在
# Persistence段落,关注rdb_last_bgsave_status和aof_last_bgrewrite_status,它们应该是ok,如果上次后台保存或重写失败了,数据就有丢失的风险,如果aof_delayed_fsync的值很大,说明AOF的同步出现了延迟。 - 主从复制健康度:在
# Replication段落,如果当前实例是从节点,要看master_link_status是否为up,表示主从连接正常,关注master_last_io_seconds_ago,这个值表示多久前从主节点收到了数据,如果这个值很大,说明复制链路可能出现了延迟(复制滞后),从节点的数据会比主节点旧。
快速了解Redis运行情况的步骤是:
- 跑一下
INFO命令,快速扫一眼connected_clients(连接数是否正常)、instantaneous_ops_per_sec(忙不忙)、used_memory(内存够不够)、mem_fragmentation_ratio(内存碎片多不多)。 - 检查错误计数器:看看
rejected_connections(有没有拒绝连接)和计算一下键空间命中率(缓存是否有效)。 - 留意延迟:通过监控感知或使用
LATENCY命令,确保响应速度在可接受范围内。 - 如果有相关配置,再检查持久化和主从复制的关键状态位是否正常。
通过关注以上这些指标,你就能对Redis的“健康状态”有一个全面而快速的把握,在问题变得严重之前及时发现并处理。
(主要信息参考来源:Redis官方文档中关于INFO命令和LATENCY命令的解释,以及常见的Redis性能监控实践建议。)
本文由黎家于2025-12-29发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/70561.html