用Redis怎么高效处理和管理海量空间数据的那些算法思路

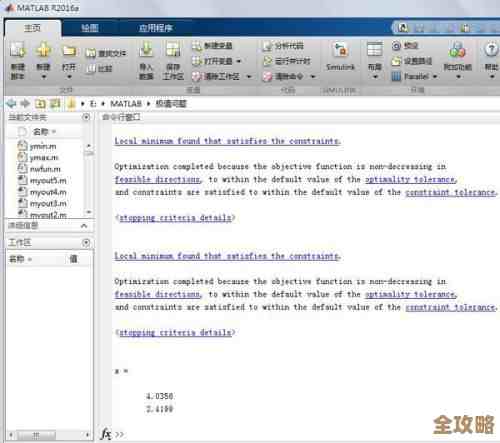
关于用Redis处理海量空间数据的高效算法思路,核心在于利用Redis内置的几种专门的数据结构和相关命令,将空间信息(比如地理位置)转换成Redis能够快速索引和查询的形式,这里主要参考了Redis官方文档中对GEO数据类型、Sorted Set(有序集合)以及GeoHash算法的说明,并结合了常见的空间查询模式。
核心基础:GeoHash编码与有序集合
最根本的思路是一种叫做GeoHash的算法,这个算法的巧妙之处在于,它能把地球上的任何一个点(用经纬度表示)转换成一串简短的字符串编码,这个编码有一个非常重要的特性:地理位置相近的点,它们的GeoHash编码的前缀是相同的,编码的长度决定了位置的精度,编码越长,表示的位置越精确。
Redis并没有直接存储GeoHash字符串,而是利用了另一种强大的数据结构——有序集合(Sorted Set),当使用Redis的GEO相关命令(如GEOADD)添加一个地理位置时,Redis在内部会做两件事:
- 计算出该位置的GeoHash值。
- 将这个GeoHash值转换成一个52位的整数,作为分数(Score)。
- 将地点名称作为成员(Member),这个分数作为排序依据,存入一个有序集合中。
这样一来,整个空间数据的管理就变成了对一个有序集合的管理,由于有序集合的成员是按照分数排序的,而分数又代表了地理位置(经过GeoHash编码),那么地理位置相近的点,它们的分数值也会很接近,这就为后续的邻近查询奠定了坚实的基础。
核心应用:高效实现“附近的人”或“周边搜索”
这是空间数据查询最经典的需求,基于上面的基础,Redis提供了一个非常直接的命令GEORADIUS(或其只读版本GEORADIUS_RO)和GEOSEARCH,它的思路非常高效:
- 输入:给定一个中心点(用户的当前位置经纬度)和一个半径(比如5公里)。
- 内部过程:Redis会利用中心点的GeoHash值,快速在有序集合中定位到分数值相近的成员范围,它不需要遍历集合中的所有成员,而是利用有序集合的跳跃表(Skip List)索引进行范围查询,这非常快。
- 过滤:在初步筛选出分数相近的成员后,Redis会使用Haversine公式(计算地球表面两点间距离的公式)对每个候选地点进行精确的距离计算,过滤掉那些虽然GeoHash前缀相近但实际距离可能超出半径的点(主要发生在边界情况)。
- 输出:返回所有在指定半径内的地点,并可以同时返回它们的距离、坐标等信息。
这个思路的优势在于,它先用GeoHash进行快速的粗筛,大大减少了需要精确计算距离的数据量,从而实现了高性能。
扩展思路:处理更复杂的空间关系
除了简单的圆形区域查询,还可以通过一些组合操作来实现更复杂的管理和查询。
-
矩形区域查询:Redis的
GEOSEARCH命令直接支持通过经纬度边界框(Bounding Box)来查询,思路是定义一个矩形区域(给出西南角和东北角的坐标),命令会找出落在这个矩形范围内的所有点,内部实现同样利用了GeoHash和有序集合的范围查询。 -
数据分片与管理海量数据:当数据量真正达到“海量”级别(例如上亿个点位)时,单个Redis实例可能无法承受,这时就需要分片(Sharding)思路,一个常见的做法是基于GeoHash前缀进行分片,因为GeoHash编码的前几位就能表示一个较大的地理区域(比如一个省或一个国家),可以将相同前N位GeoHash的点位数据存储到同一个Redis实例中,这样,当进行查询时,可以先根据查询区域计算出可能涉及的GeoHash前缀,然后只向对应的Redis分片发送查询请求,避免扫描所有数据。
-
聚合计算:想统计某个城市里不同品牌便利店的数量分布,可以结合Redis的其他数据结构:
- 用
GEOSEARCH找出该城市范围内的所有便利店。 - 遍历这些便利店的品牌信息(品牌信息可以存储在另一个Hash结构中)。
- 使用一个临时的Set或Hash来对品牌进行计数,或者直接使用Redis的
HyperLogLog数据结构进行基数统计(如果只需要大概数量且追求极致性能)。
- 用
-
地理围栏(Geofencing):比如共享单车的电子围栏,共享汽车的运营区域判断,思路是:
- 将每个围栏(一个多边形区域)作为一个Key,将其边界点序列存储在一个List或Set中。
- 当车辆上报一个新的位置时,使用
GEOADD更新车辆位置。 - 可以启动一个后台任务,定期或不定期地使用
GEOSEARCH查询车辆点附近有哪些围栏Key,然后对车辆坐标和这些围栏的多边形进行“点是否在多边形内”的几何计算(这个计算可以在应用层完成,也可以使用RedisGears等模块在服务器端完成),如果发现状态变化(比如从围栏内到了围栏外),则触发相应事件。
Redis处理海量空间数据的高效算法思路,其精髓在于将空间问题转化为Redis擅长解决的排序和索引问题,通过GeoHash编码和有序集合的结合,实现了对邻近性的快速索引,再通过命令的组合和分片策略,扩展了其处理复杂查询和海量数据的能力,整个过程避免了复杂的关系查询和全表扫描,从而保证了高性能。

本文由革姣丽于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/70055.html