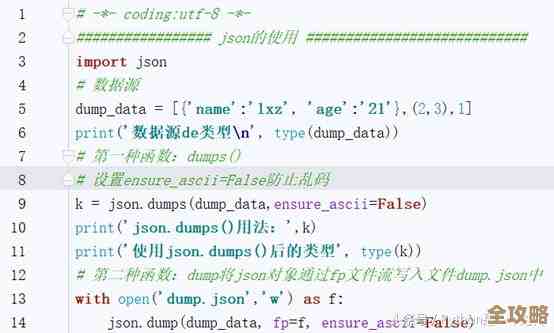
怎么用虚拟筛选数据库来快速搞定海量数据检索这事儿

说到用虚拟筛选数据库来快速搞定海量数据检索这事儿,咱们可以把它想象成一个超级高效的“智能招聘会”,你不是有一大堆(比如几百万甚至上亿)的化合物分子(就是你的“海量数据”),想从里面找出几个有希望成为新药的“潜力股”吗?挨个去面试(也就是做真实的生物实验)肯定不现实,成本太高,时间也耗不起,这时候,虚拟筛选就是这个招聘会的第一轮“AI简历筛选”和“初试”环节,帮你迅速缩小范围,把最有可能的候选人挑出来,再进行后续的“高管面试”(真实的实验验证)。
这个过程的快,主要体现在两个层面,或者说有两种主流的方法,它们像不同的筛子,可以分开用,也可以组合用。

第一种方法,叫做基于配体的虚拟筛选。 这个方法特别直观,假设你已经知道有一个“优秀员工”(这通常是一个已知的对某种疾病有治疗效果的药物分子,我们称之为“参考分子”或“药效团”),那么你的任务就是在茫茫人海中找到长得像它或者气质跟它接近的分子,这个方法的核心就是“以貌取人”。
具体怎么操作呢?计算机会提取这个“优秀员工”的各种特征,它的三维形状是胖是瘦?表面哪里凸起哪里凹陷?哪些地方带正电,哪些地方带负电?哪些原子喜欢和水亲近(亲水),哪些喜欢躲在油里(疏水)?把这些特征总结成一个“优秀员工模板”,让数据库里的每一个分子都来和这个模板比对一下,计算一个“相似度分数”,分数越高的,说明和“优秀员工”越像,就越有可能是我们想要的人才,这个过程计算起来相对简单,所以速度非常快,一天之内筛选几百万个分子是家常便饭,这就像招聘官拿着一个理想候选人的完美简历,在数据库里进行关键词和海量匹配,迅速捞出一批背景相似的简历。

第二种方法,叫做基于受体的虚拟筛选,也叫分子对接。 这个方法更进了一步,它不关心候选人长啥样,它更关心候选人能不能胜任“工作岗位”,这个“工作岗位”就是疾病相关的靶点蛋白,比如在癌症中异常活跃的一个酶,我们已经通过技术手段知道了这个“办公室”(靶点蛋白)的精确三维结构,特别是那个关键的“工位”(蛋白质上与其他分子结合、发挥功能的活性口袋)。
分子对接做的就是一件事:把数据库里的每个小分子(候选人)都试着“塞进”这个“工位”里,看看合不合适,计算机会像玩积木一样,调整小分子的姿势,计算它和“工位”的贴合程度:是不是严丝合缝?能不能形成稳定的握手(氢键)?有没有不该有的冲突?最后也会给出一个打分,叫“对接分数”,用来衡量结合的可能性强弱,这个方法更接近真实的生理过程,预测也往往更准确,但计算量巨大,比第一种方法要慢很多,即使慢,也比真实的实验快成千上万倍,它就像是初试中的“模拟实战演练”,让候选人在一个模拟的真实工作场景中表现一下,看看实际动手能力如何。
怎么把这事儿做得又快又好呢?实战中,我们常常玩“组合拳”,也就是层次筛选策略。
你不能一上来就对一亿个分子做复杂的分子对接,那得算到猴年马月,要先“过筛子”:
- 第一层,粗筛: 先用最简单的规则过滤掉明显不行的,我们想要的是能吃下去的药,那么那些分子量太大、结构太奇怪、或者含有有毒基团的分子,直接淘汰,这能瞬间去掉一大半。
- 第二层,快速筛选: 使用上面说的第一种方法(基于配体的筛选),用一个或多个已知的有效分子作为模板,快速计算相似度,选出排名前10%或5%的分子,这样,一亿个分子就只剩下几百万甚至几十万了。
- 第三层,精细筛选: 对剩下的这批“优等生”,再启动计算量大的第二种方法(分子对接),进行更精确的对接模拟,选出打分最高的几千个到几百个分子。
- 人工审查: 计算机不是万能的,科研人员会像HR最后看简历一样,人工审视这最后几百个分子的结构,凭借经验和化学直觉,挑选出几十个最有希望的“决赛选手”,送去真正的生物实验室进行测试。
通过这种层层递减的策略,虚拟筛选用计算机的“蛮力”承担了最繁重的初选工作,让研究人员能从海量数据中高效地聚焦于最有价值的极少数目标,极大地加速了药物发现的进程,据《药物化学杂志》等专业刊物中的大量文献记载,这种策略已经成为现代药物研发流程中不可或缺的标准步骤,成功案例数不胜数,它本质上是一种用计算时间换取实验时间和成本的智慧策略,让科研人员不再是大海捞针,而是能够在计算机的帮助下,“撒网捕鱼”,精准收网。

本文由瞿欣合于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/70005.html