Redis里那些瞬间变动的请求流量咋看,怎么快速了解和监控请求情况

要搞清楚Redis里那些瞬间来、瞬间走的请求流量,看看到底发生了什么,其实就像看一个热闹的十字路口的实时车流,你不能等到下班了再去数轮胎印,得有个实时监控盯着,下面就是怎么快速了解和监控的方法。
核心思路:别等出了问题再查,要一直看着。
最直接了当的方法,就是使用Redis自带的命令,这相当于你亲自站在路口用眼睛看。
Info命令是你的基础望远镜(来源:Redis官方文档 INFO命令),在Redis客户端里输入 INFO,会刷出一大堆信息,但重点看几块:
- Stats模块:这里面有
instantaneous_ops_per_sec这个值,它直接告诉你每秒处理了多少个命令,这就是最直观的“瞬时流量”,如果这个数字平时是几百,突然跳到几万,那肯定有情况。 - Commandstats模块:输入
INFO commandstats,它会列出所有命令被执行的次数、总共耗时、平均每次耗时,你就能一眼看出,是不是某个特定的命令(GET、SET,或者更复杂的KEYS *)被疯狂调用了,如果发现SET命令的平均耗时突然变长,说明这会儿写操作可能遇到了瓶颈。
光靠手动敲命令不行,因为你不可能24小时盯着终端。MONITOR命令就像在路口装了个高清摄像头,能记录下每一辆车(来源:Redis官方文档 MONITOR命令),你在客户端输入 MONITOR,Redis就会把它接收到的每一个命令,连同时间戳、客户端地址一起,实时打印出来,当流量异常时,你打开MONITOR,就能看到到底是哪些业务、哪些IP在疯狂发送什么命令。但是要极度小心,这个命令对性能影响巨大,在高负载的生成环境上长时间运行它,可能会直接把Redis搞垮,所以它只适合在紧急排查问题时,短时间内“抓包”使用。
更靠谱的方法:建立持续的监控系统。
上面说的都是临时抱佛脚,真正想快速了解情况,需要把监控常态化,这就像给路口安装一套智能交通系统。
利用Redis的慢查询日志(Slow Log)
Redis可以把执行时间超过你设定阈值的命令记录下来(来源:Redis官方文档 SLOWLOG),比如你设置slowlog-log-slower-than 10000(单位微秒,即10毫秒),那么所有执行超过10毫秒的命令都会被记下来,然后通过SLOWLOG GET命令查看,瞬间的高流量可能会引起Redis处理变慢,导致一些本来很快的命令也变“慢”了,通过慢日志能快速发现这些“受害者”,从而反推流量压力,这帮你快速定位到是哪些“慢动作”在堵塞交通。
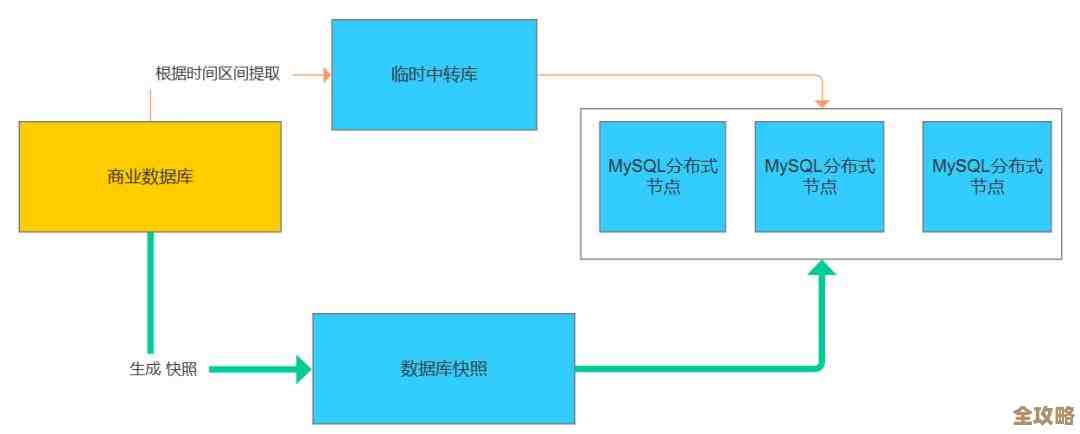
对接外部监控工具(这才是王道) 想看得清楚、看得久,必须把Redis的指标推送到专业的监控系统里,这相当于把交通摄像头的画面接到交警大队的监控大屏上。
- Prometheus + Grafana:这是现在最流行的组合之一,你需要一个叫
redis_exporter的小工具(来源:Prometheus社区提供的redis_exporter),它负责不停地从Redis实例抓取INFO命令返回的那些指标,比如连接数、内存使用量、最重要的OPS(每秒操作数)、网络输入/输出流量等,然后Prometheus负责存储这些时间序列数据,最后在Grafana里做成漂亮的图表大盘,这样你就能看到一个时间线上的流量曲线,什么时候有波峰,什么时候有波谷,一清二楚,还能设置报警规则,如果OPS连续5分钟超过1万,就发短信告警”。 - 其他商业或开源监控系统:比如Zabbix、Datadog等,它们基本都内置了对Redis的监控支持,原理都差不多,都是通过定期采集Redis的指标来生成报表和告警。
快速了解请求情况的实战步骤
当老板问你“现在Redis流量咋样?”或者收到告警时,你可以按这个顺序快速过一遍:
- 看大盘:首先打开Grafana这样的监控仪表板,看一眼OPS和网络流量的整体曲线,是不是有个尖峰?是持续性的还是瞬间脉冲?这能给你一个宏观印象。
- 看资源:接着看CPU使用率和内存使用率,高流量是否伴随着CPU打满?内存增长是否异常?这能判断流量是否造成了实际压力。
- 看细节:如果确定有问题,就去看命令统计,在监控系统里看,或者快速连上Redis用
INFO commandstats看,是不是某个命令的类型或调用量不正常?比如平时GET/SET是9:1,现在变成了1:9,说明写流量暴增。 - 抓现场(谨慎使用):如果以上步骤还无法定位元凶,比如怀疑有异常客户端在发送奇怪命令,那么在业务低峰期或备用环境上,短暂开启
MONITOR,抓取一段时间的操作日志,分析具体的命令模式。
总结一下,关键在于“常态化监控+关键指标告警”,不要等到网站卡顿了才去查,通过Prometheus等工具把OPS、延迟、连接数这些核心指标监控起来,并设置合理的阈值告警,这样当流量出现异常波动时,你就能第一时间知道,并且有足够的数据支撑你去快速分析和定位问题根源,而不是像个无头苍蝇一样临时去敲命令,平时不烧香,临时抱佛脚是看不清楚也来不及应对那种瞬间流量的。

本文由歧云亭于2025-12-27发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/69695.html