美团面试中聊到的那些让 Redis 卡住的奇怪情况和背后原因分析

主要参考了技术社区平台“掘金”上一位美团技术团队工程师的分享,并结合了其他一些技术博客的讨论,这些内容并非官方发布,而是来自一线工程师的实际面试经验和日常运维总结,所以非常贴近真实场景。
在美团这样高并发、高流量的业务环境下,Redis作为核心的缓存和存储组件,任何一点性能抖动都可能直接影响到用户体验和订单交易,面试官问这些问题,不仅仅是考知识点,更是想考察候选人有没有遇到过真实的“坑”,以及排查和解决复杂问题的思路,下面就是一些典型的、听起来有点“奇怪”但确实会导致Redis卡住的情况。
看起来CPU没跑满,但Redis就是响应变慢
这可能是最迷惑人的一种情况,你一看监控,CPU使用率可能才50%或60%,远没到瓶颈,但应用的超时告警却响个不停,问题可能出在CPU的竞争上,而不仅仅是使用率。
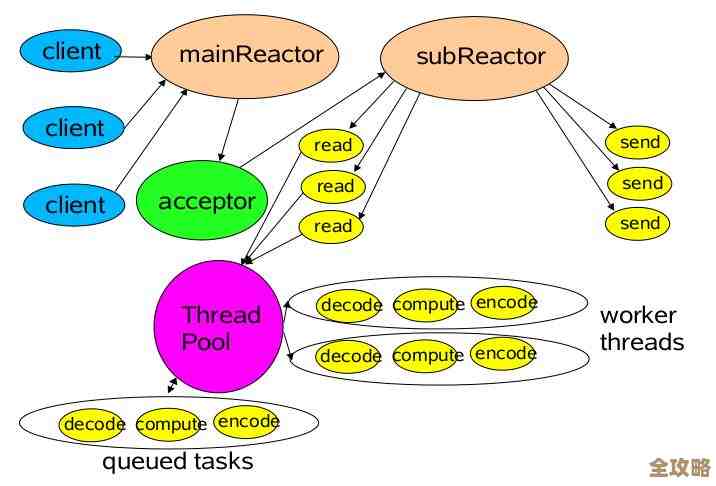
- 背后原因分析:现代的服务器都是多核CPU,Redis是单线程模型(指处理命令的主线程),它虽然能利用多核,但单个命令的执行还是绑定在一个CPU核心上的,如果这个核心被其他东西“拖累”了,即使整台服务器的CPU平均值不高,Redis的性能也会急剧下降。
- “坏邻居”效应:如果Redis进程和其他非常消耗CPU的进程(比如大数据计算任务、日志分析脚本等)被操作系统调度到了同一个CPU核心上,它们就会激烈地争夺该核心的时间片,Redis的单线程就像一条单车道,旁边突然挤进来很多大卡车,即使你的小车性能再好,也得堵着。
- CPU亲和力(Affinity)没设置好:操作系统为了平衡负载,可能会把Redis进程在不同的CPU核心之间来回切换,每次切换都会带来缓存失效(Cache Missing)的成本,新的核心需要重新加载Redis的热点数据到自己的高速缓存里,这个过程本身就会消耗时间,美团工程师的分享里提到,他们通过绑定Redis进程到固定的、独立的CPU核心上,避免了上下文切换和“坏邻居”干扰,往往能稳定地提升性能。
内存足够,却触发了SWAP,导致操作卡成幻灯片
Redis实例占用的内存明明远小于物理内存总量,但监控发现操作系统开启了SWAP(交换分区),把Redis的部分内存数据换到了慢速的硬盘上。
- 背后原因分析:这不是Redis的错,而是操作系统的内存管理机制在“捣乱”。
- 操作系统的“主动”行为:Linux内核有一个叫做
swappiness的参数,它控制着系统有多“积极”地把内存数据交换到硬盘,即使内存没用完,如果这个值设置得偏高(比如默认的60),内核可能会“未雨绸缪”地把一些它认为不常用的内存页(可能就包括Redis的部分数据)换到SWAP区,为未来可能的内存需求腾地方。 - 瞬间的“内存压力”:可能某一时刻,服务器上其他进程突然申请了大量内存,导致系统瞬间觉得内存紧张,触发了SWAP,之后那个进程释放了内存,但被换出去的Redis数据不会自动、立即地被换回来,当下一次Redis需要读取那块被换到硬盘上的数据时,就会发生一次极慢的磁盘I/O,整个请求的响应时间就从微秒级暴增到毫秒级,对于高并发的Redis来说,这简直是灾难,解决方案是将
vm.swappiness设置成一个很小的值(比如1)甚至0,告诉系统尽量别瞎折腾。
- 操作系统的“主动”行为:Linux内核有一个叫做
明明删除了大量数据,内存占用却居高不下,甚至OOM
业务上可能做了大批量的数据过期或删除,你用info memory命令查看,发现used_memory确实下降了,但操作系统显示的Redis进程占用的物理内存(RSS)却没什么变化,甚至可能因为内存碎片过高而触发内存溢出(OOM)。
- 背后原因分析:这主要和Redis的内存分配器以及碎片整理机制有关。
- 内存分配器的“吝啬”:Redis使用的是jemalloc等内存分配器,当你删除数据后,Redis虽然把内存还给了分配器,但分配器为了提升效率,并不会立即把这块内存归还给操作系统,而是自己留着,准备下次分配给新的键值对使用,这在大多数情况下是好事,避免了频繁向系统申请内存的开销。
- 内存碎片化:如果业务上频繁地写入和删除不同大小的键值对,就会在内存中产生很多“空隙”,这就是内存碎片,当碎片率很高时(可以用
info memory里的mem_fragmentation_ratio查看),即使总空闲内存很多,也可能因为找不到一块连续的、足够大的空间来存放一个新的大键,从而导致分配失败,虽然Redis从4.0版本开始支持了MEMORY PURGE命令(或配置自动碎片整理)来主动释放内存并整理碎片,但这个操作本身是主线程执行的,在执行期间会消耗大量CPU并可能阻塞所有请求,如果配置不当或在业务高峰触发,就会造成明显的卡顿。
AOF持久化刷盘策略配置不当,引发的“间歇性”卡顿
Redis的AOF(Append Only File)持久化模式,提供了几种刷盘策略,比如每秒刷盘(everysec)、每次操作刷盘(always)和不刷盘(no),看似简单的配置,选错了就会带来大问题。
- 背后原因分析:
- everysec模式下的“意外”:这是最常用的配置,意思是Redis后台线程每秒刷一次盘,听起来很平衡对吧?但如果磁盘IPS(每秒读写次数)性能不足,或者同一时刻有其他进程(如数据库、日志写入)也在疯狂写盘,导致I/O队列拥堵,那么Redis后台线程在尝试刷盘时可能会被阻塞住,这个阻塞虽然发生在后台线程,但当下一次主线程要执行AOF写操作时,如果发现上一次的刷盘还没完成(AOF缓冲区满了),主线程就会被迫等待,从而造成命令延迟,这种卡顿是间歇性的,每秒可能发生一次,排查起来很需要经验。
- always模式的“硬伤”:这个模式每个写命令都刷盘,数据最安全,但性能代价巨大,因为每个命令都要等待慢速的磁盘I/O完成,在美团这种高并发场景下,如果误用此配置,Redis的QPS会直接跌入谷底。
让Redis卡住的往往不是那些显而易见的“大”问题(比如内存爆满),而是一些更隐蔽的、与操作系统、硬件资源、配置参数相关的“细节”,面试官想看到的,正是候选人这种从现象到本质、跨层级(从应用到底层系统)分析问题的能力。

本文由钊智敏于2025-12-26发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/68933.html