Redis其实没专门挑哪个库用,默认也没指定固定数据库,挺随意的感觉

Redis其实没专门挑哪个库用,默认也没指定固定数据库,挺随意的感觉”这个说法,其实挺有意思的,它反映了很多开发者在初步接触Redis时的一种直观感受,这种感觉的来源,主要是因为Redis在设计上确实提供了一种类似于传统关系型数据库中“数据库”(Database)的概念,但它的实现方式和在实际应用中的角色却简单和随意得多,以至于让人觉得它并不是一个需要严肃对待的硬性规定。
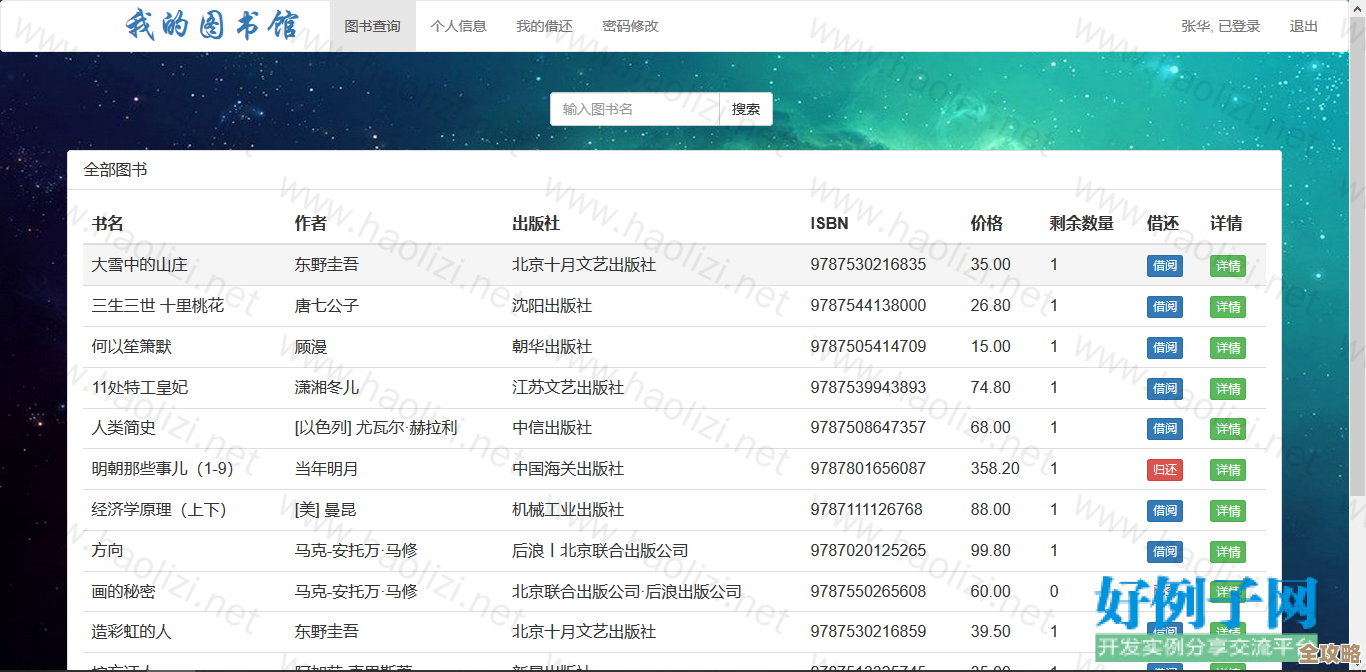
我们得明白Redis这个“库”是怎么一回事,根据Redis的官方文档,一个Redis实例默认提供了16个编号从0到15的数据库,你连接上Redis服务器后,默认会使用0号库,切换数据库的命令也非常简单,就是SELECT,比如输入SELECT 1,你就切换到了1号库,这种设计和我们熟悉的MySQL或PostgreSQL那种需要预先创建、有严格权限和模式定义的数据库完全不同,Redis的这16个库更像是预先划好的16个“储物格”,它们共享同一个Redis实例的资源(内存、配置等),但在逻辑上是隔离的,你在这个库里存的数据,在另一个库里是看不到的。
为什么说它“挺随意的”呢?这主要体现在以下几个方面:

第一,默认行为的随意性,就像前面说的,你连上Redis,它二话不说就直接把你扔进0号库,很多教程、简单的Demo项目,也就直接在0号库里操作了,根本不会提切换数据库这回事,这种“开箱即用”的体验,给初学者留下的印象就是:哦,Redis就这一个地方存数据,久而久之,0号库就成了大家心照不宣的“默认仓库”,至于其他1到15号库,好像就成了被遗忘的角落,用不用全看心情。
第二,缺乏强制性的使用规范,在复杂的业务系统中,我们可能会想着用不同的数据库来隔离不同环境(比如测试数据和线上数据)或者不同业务模块的数据,这个想法是好的,但Redis并没有提供任何强制性的机制来保证这种隔离,它没有跨数据库的事务保证,也就是说,你不能在一个事务里同时操作0号库和1号库的数据,更重要的是,像FLUSHDB命令是清空当前数据库,而FLUSHALL命令是清空所有数据库的数据——如果一个不小心在线上环境误操作,后果是灾难性的,这种“软隔离”使得所谓的数据库分隔显得有点脆弱,让人觉得并不那么可靠,因此也削弱了人们严格区分使用的动力。

第三,在集群模式下的“消失”,这种感觉上的“随意”在Redis集群(Cluster)模式下达到了顶峰,根据Redis集群的设计,它根本就不支持多数据库的概念,在集群环境下只有一个数据库,即编号为0的数据库,这是因为集群的核心数据分片机制与多数据库的概念存在冲突,当你的业务发展到一定规模,不得不使用集群时,你会发现之前费尽心思用不同数据库做的逻辑隔离,一下子都得推倒重来,这反过来也印证了,在Redis的“单机”时代,多数据库功能更像是一个为了方便而存在的“锦上添花”的特性,而非核心的、不可动摇的架构设计,既然在未来的扩展道路上它可能会“消失”,那在项目初期自然也就不会太把它当回事,随意选一个用就行了。
第四,替代方案更受青睐,随着最佳实践的沉淀,开发者们发现,要实现真正 robust 的数据隔离,有比依赖Redis内置数据库编号更好、更清晰的方法,最直接的就是使用不同的Redis实例,通过配置不同的端口,将测试、预发布、生产环境彻底物理隔离,这比在同一个实例里用不同数据库要安全得多,另一种常见做法是使用Key的前缀(Prefix)进行划分,用户相关数据的Key都写成user:123,订单数据写成order:456,通过代码规范来管理,逻辑清晰,而且在查看所有Key的时候,同类数据也自然地排列在一起,非常直观,这些方法在实践中比简单地SELECT 1或SELECT 2更可控,也减少了误操作的风险。
综合来看,“Redis没专门挑哪个库用,默认也没指定固定数据库,挺随意的感觉”这个说法,非常生动地描绘了Redis多数据库功能在实际开发中的真实地位,它存在,但并非核心;它可用,但并非最佳实践,这种“随意性”源于其设计上的轻量级隔离、在集群模式下的不支持,以及有更多优秀替代方案的现实,大多数项目和团队会形成自己的约定俗成——咱们项目一律用0号库”,或者“微服务A用1号库,微服务B用2号库”——但这种约定本身,也带着一种“反正区别不大,就这么定了吧”的随意感,这或许正是Redis这种简洁高效的系统所独有的一种哲学:提供基础能力,把复杂性和规范性更多地交给使用它的人去决定。
本文由称怜于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/68458.html