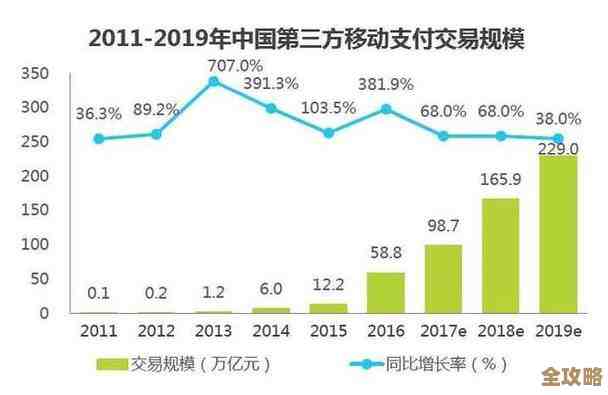
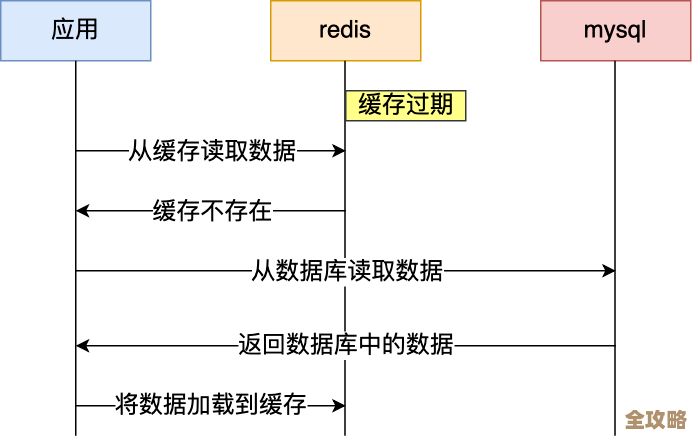
用Redis维护系统时那些容易忽略但又特别重要的运维细节和实操经验分享

根据多位资深运维工程师和数据库专家在技术社区(如知乎专栏“Redis运维踩坑记”、极客时间“Redis核心技术与实战”课程评论区精华汇总)以及个人博客(如“老张的技术博客”、“码农翻身”中的数据库篇)的实践经验分享,以下是用Redis维护系统时,那些容易被忽略但又特别重要的细节和实操经验:
别把Redis当黑盒子:核心指标要门儿清
很多人搭好Redis就只管用,监控只盯着CPU和内存使用率,这远远不够,你必须像熟悉自己的车况一样熟悉Redis的内部状态,有几个关键指标是“生命线”:

- 连接数(connected_clients):突然飙升很可能意味着客户端连接泄漏,某个应用开了连接没关闭,慢慢会把Redis拖死,要设置合理的最大连接数限制(maxclients),并监控连接数趋势。
- 内存碎片率(mem_fragmentation_ratio):这个值一般在1左右是健康的,如果远大于1.5,说明内存碎片很严重,虽然显示有内存但可能无法分配,导致不必要的键被逐出甚至写操作失败,这时候可能需要重启实例或者在高版本Redis中开启自动碎片整理。
- 持久化阻塞:无论是RDB快照还是AOF日志重写,如果数据量很大,在生成过程中可能会长时间阻塞主线程,导致服务暂停,要监控
latest_fork_usec(上次fork操作的微秒数),这个时间过长说明fork耗时久,需要警惕,对于写操作频繁的大实例,可以考虑在从节点做持久化。
配置不是一劳永逸:得跟着业务变
默认配置是通用配置,但你的业务是独特的,几个容易埋坑的配置点:
- 最大内存策略(maxmemory-policy):默认是
noeviction(不逐出,写操作报错),很多人忘了改,结果内存一满,系统就瘫痪,必须根据业务重要性设置,比如设为allkeys-lru或volatile-lru,让Redis在内存不足时自动淘汰一些键,关键是,你要清楚被淘汰的应该是哪些数据。 - 慢查询日志(slowlog):默认记录超过10毫秒的查询,这个阈值可能太宽松了,对于追求低延迟的系统,应该设为1-5毫秒,定期检查慢查询日志,能帮你发现哪些大Key或者复杂命令(如
KEYS *,HGETALL一个大哈希)正在拖慢整个服务。 - TCP-Keepalive:默认是300秒,这个时间太长了,如果客户端因为网络问题异常掉线,Redis要等5分钟才能发现并释放连接,在生产环境,建议设置为60-120秒,能更快地清理无效连接,释放资源。
数据安全无小事:备份和恢复要真演练

都知道要持久化,但很多人只做了配置,从没验证过。
- AOF重写的隐患:AOF重写时,主进程会fork一个子进程,如果此时主进程正在写入一个巨大的键(比如一个包含几百万元素的集合),子进程需要复制这个巨大的内存页,可能导致内存用量瞬间翻倍,触发OOM(内存溢出)被杀掉,要避免存在这种“巨无霸”Key。
- 备份文件要异地存放:只把RDB或AOF文件存在Redis服务器本地是危险的,如果磁盘损坏或者整个服务器宕机,备份也没了,必须有一个自动化流程,定期将备份文件传输到另一台机器或对象存储中。
- 恢复演练是必修课:至少每季度做一次真实的恢复演练,在一个隔离的环境,用你的备份文件去恢复一个Redis实例,然后验证数据是否完整、服务是否正常,纸上谈兵永远不知道会遇到什么诡异问题,比如备份文件损坏、磁盘空间不足、恢复时间远超预期等。
键的生命周期管理:不能只生不死
Redis里很多键可能是一次性使用的缓存或者临时数据,如果只写不管,就会变成“垃圾堆积场”。

- 主动设置TTL(过期时间):只要可能,就给键加上过期时间,哪怕是设置一个很长的TTL,也比永不过期要好,这能形成一个自动清理的机制。
- 定期扫描和清理:总有一些键会因为设计疏漏而成为“僵尸键”(本该过期但没设置,或不再使用但还存在),需要写脚本定期扫描(用
SCAN命令,绝对不能用KEYS *),识别并清理掉这些无用键,释放内存,按业务前缀扫描,检查最后访问时间或是否已逻辑失效。
主从复制不是高枕无忧:得盯着同步状态
搭建了主从复制就觉得高可用了,其实复制链路很脆弱。
- 监控复制偏移量(repl_backlog和slave_repl_offset):主从之间的数据同步是靠一个复制缓冲区(repl_backlog)进行的,如果从节点断开时间太长,或者主节点写入量巨大,导致从节点要同步的数据已经不在缓冲区里了,从节点就会触发全量同步(full resync),全量同步非常消耗资源和时间,所以要确保
repl_backlog_size设置得足够大,能够承受正常的网络波动。 - 从节点是否只读(slave-read-only):默认是的,但一定要确认,曾有案例因为误配置,应用写到了从节点,造成主从数据不一致,且难以发现。
- 网络分区下的脑裂:当发生网络分区时,如果客户端还能连上一个与主节点失联的从节点,就可能读到旧数据,在哨兵(Sentinel)或集群模式下,需要理解并配置好
min-slaves-to-write(Redis Cluster中类似参数是min-replicas-to-write)这类参数,它要求主节点在至少有一定数量的从节点连接时才能接受写操作,这在网络分区时能有效防止数据丢失。
客户端使用姿势很重要:服务端再好也怕猪队友
很多问题不是Redis本身的,而是客户端用法不当引起的。
- 避免“巨Key”:一个Key对应的Value体积过大(如一个List有百万元素,一个String有几百KB),会在网络传输、持久化fork、数据迁移时产生严重问题,要把大对象拆分成多个小Key。
- 避免“热Key”:某个Key的访问量远超其他Key,会造成单台Redis服务器(或集群中的某个分片)CPU负载过高,解决方案包括本地缓存、拆分成多个Key等。
- 管道(Pipeline)和事务的误用:管道能提升批量操作的效率,但一次管道中命令太多会长时间占用Redis,阻塞其他请求,事务(MULTI/EXEC)并不是回滚的,它只是确保命令顺序执行,其中一条失败不会影响后面的命令,使用时要注意。
运维Redis不能有“搭好就完事”的心态,它需要你持续地观察、分析、调整和验证,这些细节看似琐碎,但任何一个疏忽都可能在某个月黑风高的夜晚,让你的系统陷入困境。
本文由黎家于2025-12-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/67868.html