Redis集群消息同步怎么搞,效率高不高,聊聊那些实操经验和坑

聊Redis集群消息同步,其实核心是在聊两件事:一是数据怎么在不同节点间保持一致(复制),二是客户端怎么找到数据(分片和路由),这两件事做好了,同步效率自然就上去了,坑也大多出自这里。
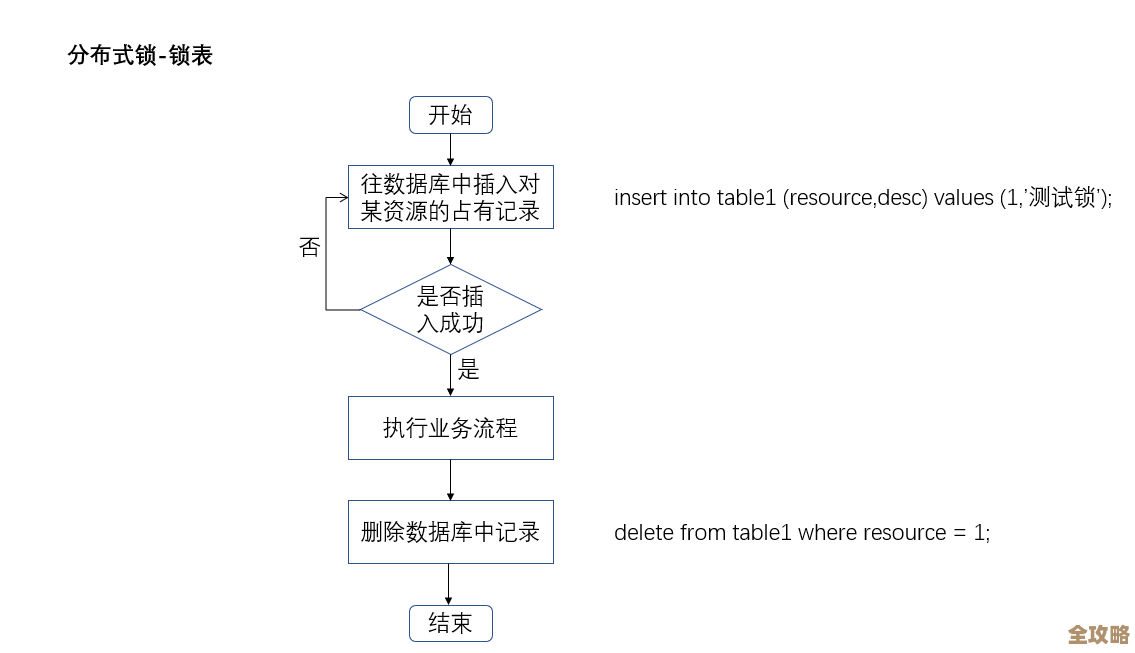
先说基础:Redis集群的两种主流玩法
现在大家用的多的主要是两种模式:一种是官方的Redis Cluster,另一种是基于哨兵(Sentinel)的主从复制+代理(比如Codis)或者客户端分片,官方的Cluster是主流,我们就以它为主来说。
官方Redis Cluster的同步机制
你可以把Redis Cluster想象成一个去中心化的网络,它把所有的数据分成16384个槽位(slot),每个节点负责一部分槽位,客户端可以连接任何一个节点,如果数据不在这个节点上,节点会告诉客户端“应该去哪个节点找”(返回MOVED重定向指令),聪明的客户端会缓存这个映射关系,下次直接连过去。
那数据同步具体怎么搞呢?靠的是主从复制,每个槽位都有一个主节点和N个从节点,所有的写操作只发生在主节点上,然后主节点会异步地把写命令同步给它的从节点们。
- 同步过程:当一个从节点刚加入,或者需要全量同步时,主节点会生成一个当前数据的快照(RDB文件),发给从节点,从节点清空自己的数据,加载这个RDB文件,之后,主节点会把期间积压的写命令(存在一个叫repl-backlog-buffer的缓冲区里)再发给从节点,从而追上主节点的状态,之后就一直通过流式的方式同步新的写命令。
- 效率如何:异步同步是保证高性能的关键,主节点处理完写请求,立刻就可以返回给客户端,不需要等待所有从节点都写完,这效率非常高,延迟基本只取决于网络带宽,但这也是“坑”的来源之一,下面会细说。
实操中的经验和坑
-
数据不一致的坑(异步复制的代价) 正因为同步是异步的,所以存在一个时间窗口:主节点写成功了,但同步给从节点的命令还在网络传输中,如果这时主节点突然宕机,即使某个从节点被选举成了新的主节点,它也会丢失宕机前那一点点还没来得及同步的数据。这是为了性能必须接受的 trade-off(权衡),如果你对数据一致性要求极高(比如金融场景),Redis Cluster的普通模式可能不太够用,可能需要等待同步的强化机制(但会影响性能),或者考虑其他更强一致性的数据库。
-
网络带宽和脑裂问题 集群节点之间需要频繁地互相通信(PING/PONG)来检测彼此是否活着,如果节点很多(比如上百个),这些心跳包会占用可观的网络带宽,更麻烦的是“脑裂”:比如网络突然出现分区,一部分节点联系不上另一部分了,每个分区都可能认为对方挂了,然后自己选出一个主节点来提供服务,导致数据冲突,Redis Cluster通过大多数原则(majority)来避免这个问题:一个节点只有得到超过半数的master节点认可时,才能成为主节点,所以部署时最好让主节点数量是奇数,并且均匀分布在不同的物理机上,避免网络分区导致整个集群不可用。
-
扩容缩容的“流量风暴” 当你增加或减少节点时,集群需要重新分配那16384个槽位,这个迁移过程是逐个key进行的,并且迁移期间,客户端可能会收到一个ASK重定向指令,让它去新的节点找数据,如果迁移的key很多很频繁,对网络和节点压力会很大。经验是:业务低峰期操作,并且监控好网络流量和节点负载,一次性迁移大量数据可能会打满网络,影响正常业务。
-
客户端的神队友or猪队友 集群的效率很大程度上也取决于客户端,一个“聪明”的客户端会缓存槽位和节点的映射关系,直接连接正确的节点,避免每次都要重定向,一个“笨”的客户端则会频繁触发重定向,增加延迟。选一个成熟稳定的Redis客户端库非常重要。
-
监控的盲点 光监控主节点是不够的,从节点的复制延迟(replication lag)是关键指标,如果从节点同步一直很慢,一旦主节点宕机,丢失的数据就会很多,或者从节点根本追不上数据,导致无法成功切换。必须把各个从节点的延迟时间都监控起来,设置好告警。
总结一下效率
在正常网络环境下,Redis集群的同步效率是非常高的,因为它核心是异步复制,读写性能接近单机Redis,水平扩展能力很强,它的高效率建立在“最终一致性”和“异步操作”的基础上,你享受了它的高性能,就意味着要理解和接受它可能带来的数据延迟和极小概率下的数据丢失风险,所谓的“坑”,其实大部分都是对这种设计理念理解不透彻导致的,实操的关键就是:规划好网络、做好监控、在业务容忍的范围内进行操作,并选择一个靠谱的客户端。

本文由歧云亭于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/67504.html