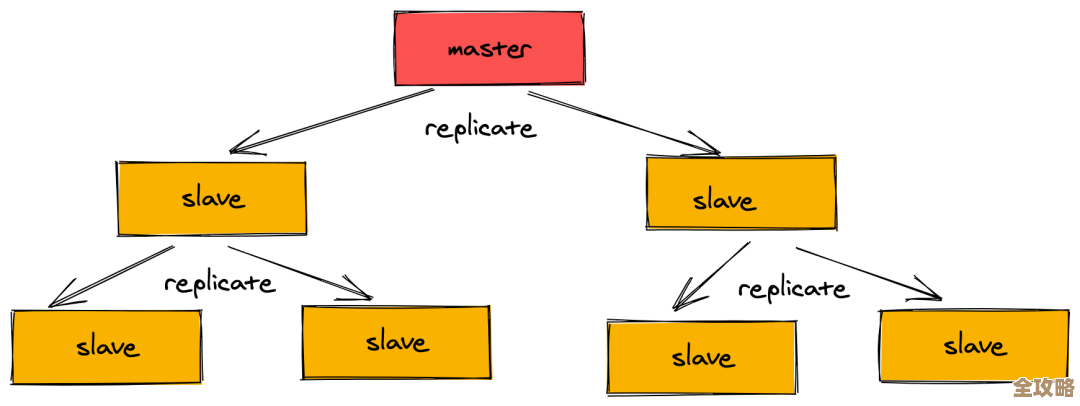
Redis那些神秘又没名字的服务,到底有啥特别吸引人的地方呢?

说到Redis,很多人可能都知道它是个特别快的“大字典”,能存各种键值对,帮网站扛住高并发,这确实是它最广为人知的魅力所在,但就像一座冰山,Redis最吸引我的,反而是那些藏在水面之下、不那么起眼甚至有些“神秘”的功能,它们没有像“缓存”或“队列”那样响亮的头衔,却能在关键时刻,用一种四两拨千斤的巧妙方式,解决那些让人头疼的工程问题。
比如说,Redis的Pub/Sub(发布/订阅)功能,它就像一个高效的“广播站”(来源:Redis官方文档对Pub/Sub机制的描述),想象一下,你的应用里有一个重要事件发生了,比如一个新用户注册成功,传统的做法可能是,注册逻辑的代码吭哧吭哧地写完用户数据后,还得亲自去调用发送欢迎邮件、初始化用户资料、发放新手优惠券等一系列服务,这个过程又长又容易出错,任何一个环节卡住都可能拖慢整个注册流程,但用了Pub/Sub就优雅多了,注册逻辑在完成后,只需要往一个叫“用户注册成功”的频道里“发布”一条消息,内容就是新用户的ID,而那些关心这个事件的邮件服务、资料服务等,早就“订阅”了这个频道,消息一发布,所有订阅者几乎能同时收到,然后各自默默地、互不干扰地去完成自己的任务,注册逻辑本身瞬间就轻松了,它只负责通知,不关心后续,整个系统的响应速度和解耦程度大大提升,这种“我发生,你处理”的模式,在处理需要多方协同的异步任务时,显得格外清爽。
另一个让我觉得特别巧妙的功能是HyperLogLog(来源:Redis官方文档对HyperLogLog数据结构的介绍),它的名字听起来有点怪,但本事不小,专门用来做巨量数据的去重计数,老板让你统计一下网站首页一天之内有多少个独立用户访问,你可能会想,这简单,每个用户访问时,把他的IP地址存到一个集合(Set)里,最后算一下集合大小就行了,但如果你的网站日活上千万甚至上亿,这个集合会变得无比庞大,占用惊人的内存,而HyperLogLog的厉害之处就在于,它可以用一个固定且非常小的内存空间(比如12KB),来估算出上亿个独立元素的个数,并且误差率可以低至1%以下,它不关心具体是哪个用户来了,只关心“大概有多少个不同的用户”,对于这种“差不多就行”的统计场景,比如统计搜索关键词的不同个数、监控大型网络的异常IP来源数量等,HyperLogLog简直就是省内存的神器,用极小的代价解决了大数据量下的基数统计难题。
还有Geospatial(地理空间)索引(来源:Redis官方文档对Geospatial数据类型的说明),这个功能让Redis瞬间变成了一个简易的地理数据库,你只需要把一些地点(比如商家、车辆)的经纬度坐标存进去,并给每个点起个名字,你就可以问Redis一些非常实用的问题:“找出我当前位置方圆5公里内所有的咖啡店”,或者“计算这两个地点之间的直线距离”,实现这些功能,你不需要引入一个笨重的关系型数据库加上复杂的地理扩展,直接用Redis几条简单的命令就能搞定,对于需要基于地理位置进行快速查询和计算的应-用,比如外卖、打车、共享单车,这个功能提供了开箱即用的便利,极大地简化了开发流程。
最后不得不提的是Redis的键过期机制(来源:Redis官方文档对EXPIRE命令的描述),它远不止是给缓存数据设置个失效时间那么简单,我们可以把它玩出很多花样,做一个限时优惠券系统,优惠券存入Redis时直接设置一个30分钟的过期时间,时间一到,键自动删除,优惠券自然失效,省去了我们手动写定时任务去扫描和清理的麻烦,再比如,做一个简单的分布式锁,锁的键可以设置一个较短的过期时间,这样即使持有锁的客户端因为故障没有主动释放锁,锁也会自动过期,避免了系统死锁的风险,这种“自带定时销毁”的特性,为很多需要时间维度的业务逻辑提供了极其简洁可靠的解决方案。
Redis的真正魅力,并不仅仅是它无与伦比的速度,更在于它提供了这些小巧而精悍的“瑞士军刀”式的工具,它们可能没有名字,或者名字听起来晦涩,但每一个都针对一类特定的、常见的编程痛点,当你遇到一个棘手的问题,绞尽脑汁想着要怎么设计数据库表、怎么写复杂的逻辑时,突然发现Redis里一个不起眼的功能正好能优雅地解决它,那种“柳暗花明又一村”的惊喜感和效率提升,才是Redis最特别、最吸引人的地方,它不仅仅是一个数据库,更是一个充满智慧的工具箱,鼓励开发者用更巧妙、更经济的方式去思考和构建系统。

本文由盘雅霜于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/67240.html