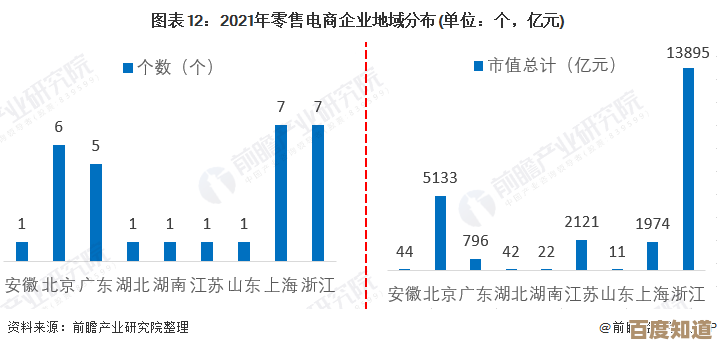
PDF转Excel高效转换,快速提取表格数据并优化工作流程

根据网络上众多办公技巧分享平台和用户实际经验,比如知乎上“有哪些让你觉得「原来这样也可以?」的神操作?”这类话题下的高赞回答,以及像“秋叶PPT”、“Office全能加油站”等知名效率工具类公众号的常年推送,PDF转Excel这个需求几乎是每个职场人都会遇到的痛点,大家普遍遇到的烦恼是,直接把PDF里的表格复制粘贴到Excel里,格式会完全乱套,数字变成一长串,文字挤在一个单元格里,后续整理的时间比手动重新输入还要长,这里要谈的高效转换,核心不在于找到一个万能魔法按钮,而在于理解不同情况下的最佳工具和方法,并把它融入你的工作习惯里,才能真正实现流程优化。

最关键的一步是判断你手里的PDF属于哪种类型,这是所有高效操作的前提,根据“简道云”等低代码平台在介绍数据采集时提到的概念,PDF表格大致分两种,第一种是“真表格”,也就是这个PDF是由Word、Excel或者WPS等办公软件直接另存为或导出生成的,这种PDF文件内部其实是有隐藏的结构信息的,只是被PDF格式“锁”住了,对付这种PDF,最简单的方法就是使用一些本身就具备强大转换功能的新版办公软件,微软Office 365里的Word,你直接右键用Word打开一个PDF文件,它会自动尝试识别其中的表格结构,并将其转换为可编辑的Word表格,虽然多了一步从Word到Excel的复制,但成功率和对齐度通常远高于直接复制粘贴,WPS Office在这方面也做得非常出色,它的“PDF工具包”里直接有“PDF转Excel”的选项,对这类“真表格”的还原度很高,并且WPS个人版是免费的,这对大多数用户来说是个福音。

另一种是“假表格”,也就是这个PDF可能是由扫描仪扫描纸质文件生成的图片式PDF,或者是由某个设计软件排版后导出的,表格的线条和文字其实都是图像的一部分,没有任何底层数据结构,这种情况就比较棘手,这时候,就需要用到“OCR”技术,OCR是光学字符识别技术的缩写,但我们可以简单地把它理解成“让电脑学会看图识字”,现在很多在线转换工具和专业的PDF编辑器都内置了OCR功能,知名的Adobe Acrobat Pro DC(注意不是免费的Acrobat Reader)就有非常强大的OCR功能,你可以在“工具”里找到“扫描和OCR”,它能够识别图片上的文字,并尝试重建表格结构,国内的一些软件,比如福昕高级PDF编辑器,也提供类似的功能,像“Smallpdf”、“iLovePDF”这类国外在线工具,或者“迅捷PDF转换器”、“嗨格式”等国内工具,也都在线提供带OCR的转换服务,它们的操作通常很傻瓜化:上传文件,选择“OCR识别”或“精准转换”等选项,然后等待处理下载即可,不过需要注意的是,在线工具涉及文件上传下载,如果表格内容涉及敏感商业数据,需要谨慎使用。
除了选择对的工具,一些小技巧也能极大提升转换后的数据质量,减少后续整理工作,很多用户在豆瓣“上班这件事”小组里分享过这样的经验:在转换前,如果原PDF页面有图片、水印或者不必要的页眉页脚,尽量先用PDF编辑工具的“截图”或“裁剪”功能把它们去掉,只保留干净的表格区域,这样可以减少OCR识别时的干扰,提高准确率,转换完成后,不要指望百分百完美,立刻进行一次快速的数据校验至关重要,重点检查以下几项:数字有没有被错误识别(比如把“0”识别成“O”,把“1”识别成“l”);货币符号、百分比符号的位置是否正确;单元格的合并是否合理,养成这个“转换-校验”的习惯,比事后发现错误再从头排查要高效得多。
如何将这一套动作优化成顺畅的工作流程?这需要一点前瞻性思维,像“少数派”网站上的效率专家经常强调的,自动化是提升效率的终极武器,如果你需要频繁处理来自固定来源、格式相似的PDF表格(比如每周从固定系统下载的销售报表),可以研究一下更高级的解决方案,一些专业的批量处理工具(如ABBYY FineReader)支持一次性转换大量PDF文件,更进一步,如果你懂一点编程,可以用Python里的库(如Tabula-py、Camelot)来写一个简单的脚本,实现一键批量转换和基础的数据清洗,这几乎是最高效的方式,但需要一定的学习成本,对于绝大多数普通用户而言,建立起“判断PDF类型 -> 选择合适的工具(WPS/在线OCR/专业软件) -> 转换后快速校验”这个清晰的思维路径,就已经能节省下大量不必要的时间浪费,让PDF不再成为数据处理的拦路虎。
本文由雪和泽于2025-11-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/58798.html