专用GPU资源满载运行,共享GPU资源维持稳定可用状态

(信息主要综合自各大云服务商如阿里云、腾讯云、华为云的官方产品文档、技术博客以及行业分析报告中对GPU资源使用模式的描述。)
当我们谈论在云端使用图形处理器(GPU)进行高强度计算时,比如训练一个复杂的人工智能模型、进行大规模的图形渲染或者运行精密的科学模拟,通常会遇到两种主要的资源供给模式:专用GPU和共享GPU,这两种模式的目标都是为了满足用户的计算需求,但它们在资源分配方式、性能表现和适用场景上有着根本的不同,用户期望的理想状态往往是:当需要全力以赴完成核心任务时,有专属的、强大的GPU资源能够达到满载运行,确保任务以最快速度完成;对于那些不那么紧急或计算量稍小的辅助性任务,能有稳定且成本更优的共享资源来维持其平稳运行,理解这两种模式如何协同工作,对于高效、经济地利用云计算资源至关重要。
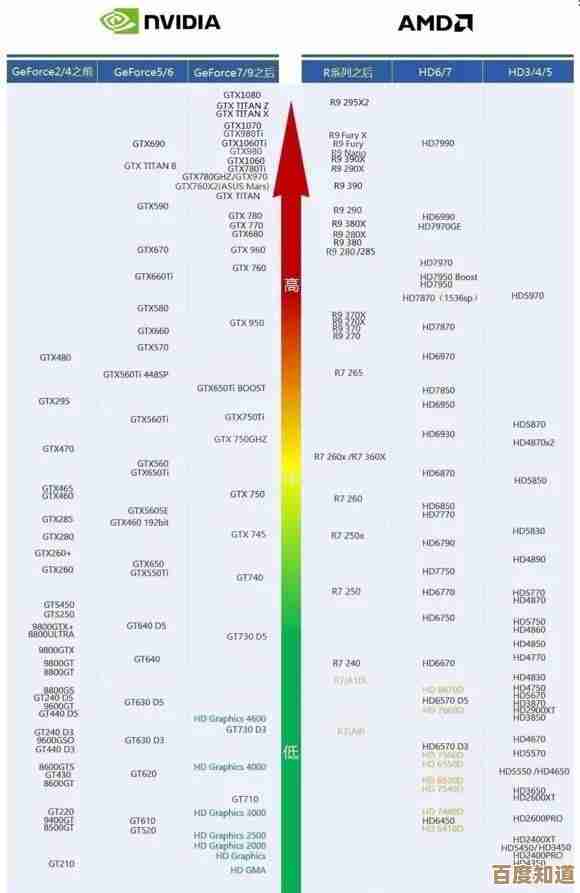
我们来深入了解一下“专用GPU资源满载运行”的含义和重要性,专用GPU,顾名思义,就是为用户独享的物理GPU卡,云服务商将一整块实体GPU的计算能力完全分配给一个用户实例,在租用期间,这块GPU的所有核心、内存和计算能力都专属于该用户,不与其他人分享,这种独占性带来了几个关键优势,最核心的一点是性能的可预测性和极致性,由于没有其他用户竞争资源,使用者可以放心地将计算任务推向极致,让GPU的利用率达到或接近100%(即满载运行),这对于需要持续、高强度计算的任务来说是至关重要的,在训练一个深度神经网络时,算法的迭代过程需要反复进行大量的矩阵运算,GPU的每一个计算单元都会被充分调动起来,满载运行意味着模型训练的每一步都在以硬件允许的最快速度进行,能够显著缩短从数据输入到模型产出所需的时间,直接提升了研发效率和生产效率,阿里云在其GPU计算型实例的产品介绍中就强调,这类实例适合深度学习训练、科学计算等场景,能够提供稳定的高性能计算能力,这种稳定性源于资源的独享,避免了因邻居用户突然发起大规模计算而导致的性能波动或“噪音”干扰,专用GPU通常配备有更强大的散热系统和更直接的硬件访问路径,进一步保障了在长时间满载运行下的稳定性和可靠性,用户可以像使用本地的高性能工作站一样,对资源拥有完全的控制权。
独占顶级资源通常意味着较高的成本,并非所有任务都需要如此强大的、持续满负荷的计算能力,这时,“共享GPU资源维持稳定可用状态”的价值就凸显出来,共享GPU是一种通过技术手段将一块物理GPU虚拟化,并将其计算能力分配给多个用户实例同时使用的模式,它的核心设计目标是在保证基本可用性的前提下,提高资源的利用效率,从而降低用户的使用成本,腾讯云在其轻量级GPU服务器产品页面上指出,这类产品适用于AI推理、图形图像处理、云游戏等场景,这些场景虽然也需要GPU加速,但对计算资源的持续峰值要求不如训练阶段那么高,维持共享GPU资源的“稳定可用状态”是一个技术上的挑战和追求,云平台的服务商需要通过先进的调度算法和隔离技术,确保多个用户的任务在同一块物理GPU上运行时,彼此之间不会相互干扰,每个用户都能获得事先承诺的那部分计算能力(四分之一或八分之一颗GPU),并且这个性能表现是相对稳定的,不会因为同一台物理机上的其他用户负载突然变化而出现剧烈的性能波动,华为云在介绍其GPU虚拟化技术时提到,通过分时复用和空间切分等技术,可以实现GPU资源的精细化管理和隔离,保障用户获得一致的体验,这种模式非常适合处理间歇性的、对延迟不太敏感的计算任务,比如对已经训练好的人工智能模型进行应用(即推理),或者在线播放一段经过GPU加速编码的视频,用户无需为整个GPU付费,只需为实际消耗的资源量付费,极大地节约了成本。
将专用GPU的满载运行与共享GPU的稳定可用结合起来,就构成了一种高效且具有成本效益的混合资源使用策略,一个典型的工作流可能是这样的:一个开发团队在模型研发的关键阶段,租用专用的GPU实例,让其7x24小时满载运行,以最快的速度完成模型的训练和调优,一旦模型训练完成,需要部署到线上为终端用户提供服务(即推理阶段),由于推理请求通常是断续到来的,且对单次计算的耗时要求不如训练阶段苛刻,团队就可以将模型部署到共享GPU实例上,这样,在用户访问量低的时候,资源不会被浪费;在访问量高的时候,共享集群也能通过负载均衡平稳处理请求,同时保持远低于专用GPU的成本,这种按需取用、分配合适资源给合适任务的思路,正是云计算弹性与效率优势的集中体现。
专用GPU资源与共享GPU资源并非相互替代,而是相辅相成的两种服务形态,追求专用资源的满载运行,是为了攻克计算密集型的核心任务,追求极致的速度和效率;而依赖共享资源的稳定可用,则是为了以更经济的成本处理日常的、轻量级的计算负载,保证业务的连续性和成本的可控性,一个成熟的云用户会根据自身业务的具体需求,灵活搭配使用这两种资源,从而在性能和成本之间找到最佳平衡点,实现计算资源利用的最优化。

本文由芮以莲于2025-11-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/57471.html



![[QQ手机浏览器]极速安全,畅享便捷移动上网新体验](http://waw.haoid.cn/zb_users/upload/2025/11/20251105214053176235005313774.jpg)