从架构到互联:探究最新CPU天梯图背后的性能飞跃与技术革新

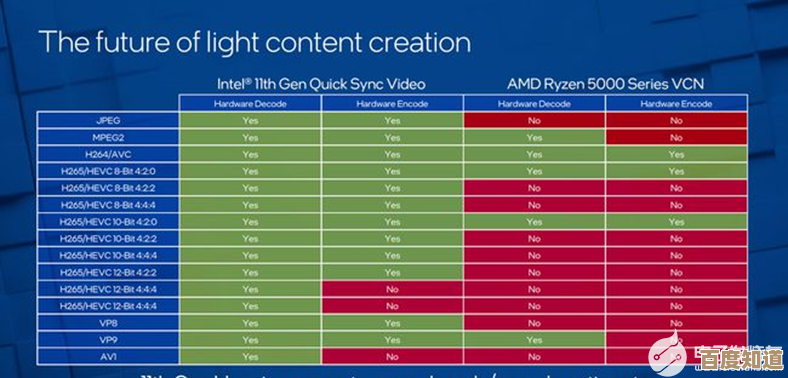
哎,说到CPU天梯图这事儿,我前两天还盯着那张密密麻麻的图发了好一会儿呆,你说现在这玩意儿,哪还像几年前那样一目了然啊,简直成了一幅抽象画,什么P核E核、3D缓存、chiplet…名词一堆,感觉买个CPU都快成半个架构师了,行吧,那咱就聊聊,这图背后那些弯弯绕绕的技术,到底是怎么让性能像坐火箭似的往上蹿的。
记得大概…五六年前吧,天梯图还是个挺线性的东西,主频高一点,核心多几个,排名就往上挪一挪,规律简单粗暴,那时候大家比的是什么?嗯…主要是制程工艺,14纳米挤到10纳米,再挤到7纳米,每次进步都像从毛巾里再拧出几滴水,费劲,但确实有效,可现在?完全不是那么回事了,你光看纳米数都快判断不了强弱了,英特尔和台积电在数字定义上都快打起来了,感觉像在玩文字游戏。
真正的变化,我觉得是从“架构”这个词变得不那么“单纯”开始的,以前架构更新,像是给同一个发动机做优化,提升燃烧效率,现在呢,简直是把发动机拆了,重新想象“动力”该怎么产生,就比如英特尔那个大小核混合架构,刚出来时多少人骂啊,觉得是投机取巧,但你想啊,这背后其实是种“精打细算”的哲学:别让彪悍的大核去处理后台那些鸡毛蒜皮的小任务,太浪费能量了,交给小巧省电的小核去干,这就像家里既有能颠大勺的猛火灶,也有热杯牛奶的小奶锅,各司其职,整体效率反而高了,这思路一开,天梯图就不再是比谁胳膊粗,开始比谁更“聪明”了。
然后就是AMD掀桌子的玩法:chiplet,这招太狠了,直接把CPU从一个完整的“大饼”切成几块“小披萨”,好处是啥?良品率飙升啊,一小块芯片出问题的概率总比一大块低吧,成本也下来了,更绝的是,它能像搭乐高一样组合,你需要超多核心?行,我多粘几块计算芯片上去,你需要超快通信?好,我换个更牛的内连“桥梁”,这种模块化,让CPU设计摆脱了物理上的很多限制,性能天花板一下子被捅高了,你看天梯图上,那些线程撕裂者之类的怪物,多半是靠这招堆出来的。
还有个让我觉得特别有意思的点是,缓存……这个以前在参数表里不太起眼的家伙,现在成了兵家必争之地,AMD搞的那个3D V-Cache,直接给CPU盖了个“ loft 复试小阁楼”,把缓存堆得跟小山似的,结果呢?游戏性能蹭蹭涨,这说明啥?说明数据的“就近原则”太重要了,核心再快,喂不饱数据也是白搭,这就像你有个超级大脑,但所有书都放在一公里外的图书馆,那还不如一个普通大脑,但需要的书就在手边,这种对内存子系统近乎极致的优化,也是天梯图排名暗地里较劲的关键。
再说说互联,这个就更像幕后英雄了,核心之间、芯片之间、甚至CPU和GPU之间,数据怎么跑得快、不乱套,全靠互联技术,PCIe标准从4.0到5.0再到眼瞅着来的6.0,带宽翻着跟头涨,这就像是把乡间小路升级成双向十六车道的高速公路,数据堵车的情况少多了,没有这么强悍的互联,chiplet设计根本玩不转,那么多小芯片之间要是通信延迟高了,性能反而会下降,所以你看,天梯图上的每一次飞跃,背后可能都是一场互联技术的静默革命。
所以现在再看天梯图,我感觉它已经不是一张简单的性能排名表了,更像是一张浓缩的技术路线图,它记录着厂商们是怎么在物理极限的墙脚下,挖地道、搭梯子、甚至想办法把墙拆了的过程,这里面有架构师的奇思妙想,有工程师对功耗和散热的死磕,也有对软件生态的艰难适配… 有时候想想也挺感慨的,我们这些用户,只是看到了一个简单的排名和分数,但背后是无数人好几年绞尽脑汁的成果。
下次你再打开天梯图,别光盯着最顶上那几款流口水了,稍微琢磨一下,它为什么能站在那儿,可能就会发现,这小小的图表里,藏着一部波澜壮阔的微缩科技史,而这部历史,还远没到写完的时候呢… 听说下一波又要搞什么硅光互联、近存计算了,哎,到时候这天梯图,怕不是要变成3D立体的了吧。

本文由颜泰平于2025-10-22发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/36587.html