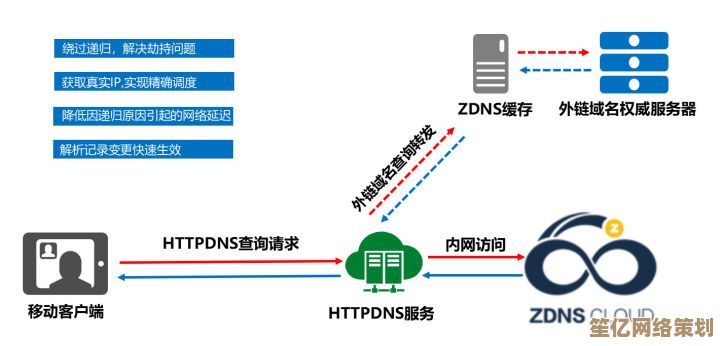
轻松获取海量PDF资源,高效下载服务让资料收集更便捷

轻松获取海量PDF?我的资料收集血泪史与笨办法
凌晨三点,屏幕的光刺得眼睛生疼,论文的参考文献列表像一张嘲讽的脸——第17条,那个该死的PDF,学校数据库没有,谷歌学术跳转的出版社页面赫然标价39.99美元,我瘫在椅子上,胃里翻腾着咖啡和绝望的酸涩,那一刻,我对着黑暗发誓:再也不要被一份PDF逼到绝境。
后来学乖了。 找资料这事儿,不能只靠一根筋撞南墙,有些门道,是熬夜熬出来的。
“神秘花园”的诱惑与荆棘: 朋友曾神秘兮兮甩给我一个网址:“试试这个,啥都有!” 点进去,简陋的界面,搜索框像通往异世界的入口,输入关键词,瞬间弹出几十个相关PDF——研究报告、绝版电子书、冷门会议论文集……心跳加速,指尖发凉,点下下载按钮时,甚至下意识环顾四周,仿佛在做什么见不得光的事。这种“资源聚合站”确实像阿拉丁神灯,但擦亮神灯的代价可能是隐私泄露、恶意软件,甚至法律风险。 下载的文件名有时是乱码,打开发现内容驴唇不对马嘴,或者被插入了诡异的广告链接,效率?有时确实快,安心?从未有过,这种“捷径”的阴影,始终挥之不去。

学术利器:别只盯着学校那扇门: 毕业离校,VPN失效,突然成了学术圈的“流浪汉”?别慌。Library Genesis (LibGen) 和 Sci-Hub 这类名字,在研究生的小圈子里几乎是心照不宣的“地下氧气”。 当你在某个付费墙前碰得头破血流,把论文DOI(那串独一无二的数字身份证)复制进Sci-Hub的搜索框,几秒后PDF哗啦一下弹出来——那种感觉,堪比沙漠里找到绿洲,它们游走在灰色地带,域名像打地鼠一样更换,使用时总带着点“踩钢丝”的心虚。合法替代品?试试Crossref Metadata Search,它本身不提供全文,但像个超级指路牌,精准告诉你目标文献的官方“家门”开在哪里,甚至标注哪些是开放获取(Open Access)的——这才是能光明正大走进去的正门。
笨功夫,有时是快功夫: 别看不起“笨办法”,我电脑里有个文件夹,名字就叫“捡破烂”,里面分门别类存着各种偶然发现的宝藏:行业白皮书发布页面的链接(比如某某咨询公司官网的“Insights”栏目)、政府机构的公开数据库入口(像国家统计局的年鉴下载区)、甚至是我喜欢的某位学者个人主页上分享的讲义和预印本。这些地方更新不快,资源也不“海量”,但胜在精准、权威、免费且绝对安全。 建立自己的“资源地图”,定期去这些“老地方”转转,比漫无目的地冲进“资源海洋”里捞针,往往更有效率,上周写市场分析,急需某细分领域数据,就是在市统计局官网的“数据服务”子目录深处,挖到了前年的专项调查报告PDF——官方出品,数据扎实,直接引用毫无压力。

下载器?小心甜蜜陷阱: “一键下载全网PDF!” 这种口号太诱人了,我也试过几个浏览器插件和所谓“万能下载工具”,结果呢?要么疯狂弹广告,要么偷偷占用系统资源让电脑卡成幻灯片,最糟的一次,下回来的根本不是我要的论文,而是一堆加密的垃圾文件,杀毒软件尖叫了整整五分钟。高效?省下来的时间全搭进去杀毒和重装系统了。 现在我的原则是:非必要,不安装。 浏览器自带的“另存为PDF”功能,或者老老实实用学术数据库提供的官方下载按钮,最慢,但也最稳。
说到底,获取PDF没有真正的“轻松”神话。 海量资源的背后,要么是版权模糊的灰色风险,要么是建立个人资源库的长期积累,要么是精准锁定官方渠道的检索能力,与其追求虚幻的“一键获取”,不如磨炼自己的信息嗅觉:
- 明确目标: 你到底要什么?模糊的关键词只能带来垃圾信息。
- 锁定源头: 它是学术论文?找数据库或预印本平台,是行业报告?盯紧咨询公司或协会官网,是政府文件?直奔.gov域名。
- 善用“合法免费”: 开放获取(OA)期刊、机构知识库、作者自存档(如ResearchGate, Academia.edu,需谨慎甄别版本)、政府公开信息,都是金矿。
- 建立个人“资源池”: 收藏靠谱的官网、数据库、开放目录,定期维护,如同打理自己的知识花园。
资料收集的“便捷”,从来不是靠某个神奇按钮,而是在信息迷雾中点亮一盏属于自己的灯,知道去哪里找,如何安全地拿到手。 省下和垃圾信息、恶意软件、付费墙搏斗的时间,哪怕只够多睡半小时,也是实实在在的高效,祝各位找资料不折腾,下文献手不抖。
本文由符海莹于2025-09-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/14881.html